
ファイル入出力の基本 (IO モデル) を勉強する
東京Node学園祭2012 アドベントカレンダー の 20 日目の記事ですが, あんまり Node は登場しません...
Node.js がでたての頃は C10K 問題とからめて説明されることが多かったかとおもいます. C10K 問題といえば次の有名な記事がありますが,
TheC10kProblem - 「C10K問題」(クライアント1万台問題)とは、ハードウェアの性能上は問題がなくても、あまりにもクライアントの数が多くなるとサーバがパンクする問題のこと
はじめて読んだ時は内容をさっぱり理解できませんでした. 特にノンブロッキング, 多重化, 非同期といった IO まわりがわからずついていけなかったので, 当時しらべたり試したことを紹介したいと思います.
はじめに
おもに詳解 UNIX プログラミングを参考にしているため, 内容が古いところがあるかもしれません. またサンプルコードや図も最後に紹介する参考文献のものを参考にして作成しました.
通常のブロッキング IO
まずは通常のブロックするファイル入出力から. ふつうにファイルを開き, 読み書きします. これには open, read, write, close といったシステムコールを使います. open 関数でファイルを開いてファイルディスクリプタを取得, read や write はファイルディスクリプタを指定して読み書きを行うという具合です. 次は標準入力から読んで標準出力に書き出す例です.
#include#include #include #include #include int main (void) { int n; int bufsize = 8192; char buf[bufsize]; while ((n = read(STDIN_FILENO, buf, bufsize)) > 0) if (write(STDOUT_FILENO, buf, n) != n) { fprintf(stderr, "write error"); exit(1); } exit(0); }
- 標準出力から 8192 バイトずつ read し, 標準出力へ write しています
- 通常は標準入力・出力・エラー出力のオープン・クローズはシェルが面倒を見てくれるため, この例では自分で open, close をしていません.
- 標準入力がファイルディスクリプタの 0 番, 標準出力が 1, 標準エラー出力が 2 に割り当てられてプロセスに渡され, プロセス終了時に勝手にクローズします
- この例では unistd.h の STDIN_FILENO, STDOUT_FILENO を利用しています.
実行するとこんなかんじです.
$ gcc -Wall blocking.c $ echo 'hello world' | ./a.out hello world
この例では read が完了するまでの間と write が完了するまでの間, プロセスがブロックされています.
ノンブロッキング IO
open の第二引数にはフラグを渡すことができます. 読み込み専用や書き込み専用にするおなじみのフラグもありますが, 今回はこの中の O_NONBLOCK というフラグに注目します. O_NONBLOCK を指定して open したファイルディスクリプタは, オープン操作と入出力操作でブロックしないように設定されます. *1
O_NONBLOCK で "ブロックされなくなる" ということをもう少し詳しく見て行きましょう. システムコールは "低速" なものとそれ以外の無期限にプロセスを止めてしまうものに分類できます. 低速なシステムコールは例えばディスクファイルへの入出力です. ディスクが低速の場合時間がかかりプロセスがブロックすることもありますが, 成功, あるいは失敗した場合でもいつかは処理がプロセスに戻ってきます. 一方データが整っていないファイルからの読み込みや, データをすぐに受信できないファイルへの書き込みは無期限にブロックしてしまいます. 例えば次の例で何も入力がない場合は, 標準入力からの入力をずっと待ち続けることになります.
$ read i && echo $i
O_NONBLOCK で回避できるのはこのようなケースです. 操作が完了できない場合に, 永遠に待つ代わりにエラーが返されるようになります.
では次の例を見て見ましょう.
#include#include #include #include #include #include #include #include void set_fl(int fd, int flags); void clr_fl(int fd, int flags); char buf[100000]; int main(void) { int ntowrite, nwrite; char *ptr; /* 100000 byte 読み込む. 読み込んだバイト数を標準エラー出力に出力. */ ntowrite = read(STDIN_FILENO, buf, sizeof(buf)); fprintf(stderr, "read %d byts\n", ntowrite); /* 標準出力に O_NONBLOCK を指定 */ set_fl(STDOUT_FILENO, O_NONBLOCK); for (ptr = buf; ntowrite > 0; ) { errno = 0; /* 標準出力に書き込み */ nwrite = write(STDOUT_FILENO, ptr, ntowrite); /* 書き込んだバイト数と, エラーが有った場合はその内容を標準エラー出力に出す */ fprintf(stderr, "nwrite = %d, errno = %d, err_message = '%s'\n", nwrite, errno, strerror(errno)); /* 読み込んだデータすべてを出力するまでループする */ if (nwrite > 0) { ptr += nwrite; ntowrite -= nwrite; } } clr_fl(STDOUT_FILENO, O_NONBLOCK); return 0; } void set_fl(int fd, int flags) { int val; if ((val = fcntl(fd, F_GETFL, 0)) < 0) { fprintf(stderr, "fcntl F_GETFL error"); exit(1); } val |= flags; /* turn on flags */ if (fcntl(fd, F_SETFL, val) < 0) { fprintf(stderr, "fcntl F_SETFL error"); exit(1); } } void clr_fl(int fd, int flags) { int val; if ((val = fcntl(fd, F_GETFL, 0)) < 0) { fprintf(stderr, "fcntl F_GETFL error"); exit(1); } val &= ~flags; /* turn flags off */ if (fcntl(fd, F_SETFL, val) < 0) { fprintf(stderr, "fcntl F_SETFL error"); exit(1); } }
- 基本は先ほどと同様に標準入力から読み込んで標準出力へ書き出す処理ですが以下の点が異なります
- 標準出力のファイルディスクリプタに O_NONBLOCK を指定
- エラー内容と読み書きしたバイト数を標準エラー出力に出力
- set_fl, clr_fl はファイルディスクリプタへフラグをセット・外す処理を行う関数です
- fcntl というシステムコールが登場していますが, これはすでにオープンしているファイルディスクリプタの属性を変更するものです. 標準出力はオープンされてプロセスに渡されるので, 今回の例では fcntl でフラグをセットしています.
このプログラムを, 標準入出力をファイルにリダイレクトして実行すると, 次のように一度に 100000 バイト読み込んでから, 一度に 100000 バイト書きこむという動きをします.
$ ls -l ./bigfile.txt -rw-r--r-- 1 kosei kosei 1250625 Nov 3 20:07 ./bigfile.txt $ gcc -Wall -o nonblock_test nonblock.c $ ./nonblock_test < ./bigfile.txt > result.log read 100000 byts nwrite = 100000, errno = 0, err_message = 'Success'
では標準出力を端末にするとどうでしょうか. 見やすいようにエラー出力をファイルにリダイレクトして実行します.
$ ./nonblock_test < ./bigfile.txt 2> result.log ... 略 ... $ cat result.log read 100000 byts nwrite = 3839, errno = 0, err_message = 'Success' nwrite = 3839, errno = 0, err_message = 'Success' nwrite = -1, errno = 11, err_message = 'Resource temporarily unavailable' nwrite = -1, errno = 11, err_message = 'Resource temporarily unavailable' nwrite = -1, errno = 11, err_message = 'Resource temporarily unavailable' nwrite = -1, errno = 11, err_message = 'Resource temporarily unavailable' nwrite = 3839, errno = 0, err_message = 'Success' nwrite = -1, errno = 11, err_message = 'Resource temporarily unavailable' ... 略 ... nwrite = 4025, errno = 0, err_message = 'Success'
ファイルの中身は端末に表示されますが, このようにエラーが出ています. 端末が一度に受け取ることができるバイト数が決まっているので, 端末のバッファがいっぱいになった時点からそれを書きだしてフラッシュするまでの間, errno = 11 が read に返されているという状況です. 標準出力の準備ができるまで for ループで何度もチェックし, 準備ができているときに書き込みを行なっています. 言い方を変えると, for ループで書き込みができるようになるまでポーリングしていることになります.
標準出力へ O_NONBLOCK を指定しなければエラーは出ず一度に書きだされます. ただしプロセスはブロックされていることになります.
$ emacs nonblock.c (set_fl(STDOUT_FILENO, O_NONBLOCK) のところをコメントアウトしてコンパイルしなおす) // set_fl(STDOUT_FILENO, O_NONBLOCK); $ gcc -Wall -o nonblock_test nonblock.c $ ./nonblock_test < ./bigfile.txt 2> result.log ... 略 ... $ cat result.log read 100000 byts nwrite = 100000, errno = 0, err_message = 'Success'
IO 多重化
次に登場するのは IO 多重化 (multiplexing) です.
Web サーバなど一つのプロセスで複数のファイルディスクリプタを扱いたいケースを考えます. 例えばクライアントからのリクエストを受けローカルのファイルにアクセスするような場合は, リクエストの読み書き, ローカルファイルへの読み書きで 4 つのファイルディスクリプタの読み書きをしないといけません. このときの問題は, どれか一つでも読み書きがブロックしていると他が全く使えなくなってしまうということです.
解決策としては以下があります.
- 全てのディスクリプタに対して O_NONBLOCK を指定する. この場合ポーリングが必要なので無駄が多い
- プロセスを fork する. 各プロセスは読み書き 1 つずつのファイルのみを扱うようにする. この場合プロセス間通信が厄介.
- 非同期 IO (後述) を使う. 未対応の環境があったり, シグナル通知の取り扱いが煩雑だったりする.
- IO 多重化を使う
IO 多重化はそのプロセスが扱うファイルディスクリプタを一括して保持し, そのうちどれかが準備できるまでブロックする関数です. 関数が戻ってくるとどのディスクリプタが準備できているのかわかります. select, poll, epoll などのシステムコールがあります.
select
ファイルディスクリプタの集合を与えて, 指定した時間待ちます. (無限に待つことも, 待たずに即座に結果を得ることもできます.) いずれかのファイルディスクリプタの準備ができるか, タイムアウトしたら処理が戻ります.
select の動作イメージは,
- select が呼ばれると karnel は対象のファイルディスクリプタの一覧 (ファイルディスクリプタの監視テーブル) をコピーする.
- イベント (ディスクリプタの準備ができたり, タイムアウトしたり) が発生するとディスクリプタの一覧を更新する
- ファイルディスクリプタの監視テーブルをユーザープロセスに戻す
- ユーザプロセスは監視テーブルをチェックし 準備ができているディスクリプタを特定. 読み書きを行う
select の問題点は, ディスクリプタの一覧を毎回普通に線形探索しているので, select するごとに O(n) (n は最大ファイルディスクリプタ + 1) の計算量が発生することです. 扱うファイル数が増えるごとに線形に時間がかかってしまいます. また扱うことのできるファイルディスクリプタ数にも制限があります (1024 など).
poll
select のようなファイルディスクリプタ数の制限がありません. (正確には poll 関数が上限を設けてないという意味でオープンできるファイル数などカーネルの設定値による縛りはあります.) ただし select と同様線形探索によるパフォーマンスの問題は依然残っています.
epoll, kqueue, /dev/poll
select や poll はイベントが起こった場合にディスクリプタの監視テーブルをまるごとチェックしないと行けないことに対し, epoll はイベントが発生したディスクリプタだけを通知してくれます. そのためディスクリプタを O(1) で取り出すことができ, select や poll のパフォーマンスの問題が解消されているのが特徴です. linux kernel 2.6 以降で対応しているそうです. BSD, Soralis の場合それぞれ kqueue, /dev/poll という仕組みで同等のことができます.
問題点としてはプラットフォームによってインターフェースが異なっていて, そこを吸収するものが必要になることです.
非同期 IO
非同期 IO では read や write の完了時にプロセスに通知が来ます. 通知にはシグナルとスレッドベースのコールバックの二種類があります. IO 多重化との違いは,
- select や poll 関数でポーリングしてディスクリプタをチェックすることが不要で, 読み込み・書き込みが完了した時点で非同意に通知が来る
- 多重化の場合ディスクリプタの準備ができたことが select 関数などでわかり, そこから読み書きを開始するが, 非同期 IO の場合読み書きが完了したあとに通知が来る.
実装には POSIX AIO や libaio があります.
こちらもインタフェースや実装差異の吸収が問題点としてあげられると思います. また実装の貧弱さも指摘されているそうです.
ここまでのまとめ
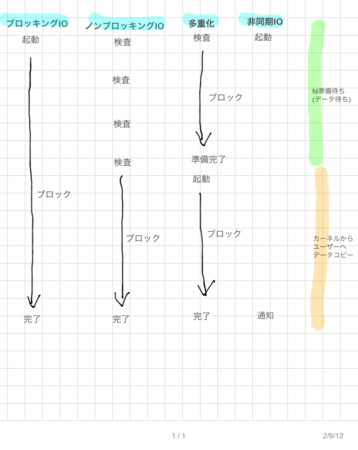
(図はクリックで大きいものが見られます)
ここまでのまとめです
- 通常のブロックする IO はシンプルだが, 読み書きの間プロセスがまたされる
- O_NONBLOCK を指定したノンブロッキングな IO の場合ファイルディスクリプタの状態をブロックせずにチェックできるが, ポーリングしないといけない
- IO 多重化の場合複数のファイルディスクリプタを効率的に扱うことができるが, インタフェースの差異がある
- 非同期 IO の場合ディスクリプタのチェックや実際の読み書きすらブロックされないが, 枯れていない.
ライブラリ
libev や libevent といった, IO 多重化の差異を吸収して抽象的なインタフェースを提供しているライブラリがあり, 以前の Node や ngin などで使われています. さらに libuv は windows も含めたマルチプラットフォームに対応するために作られたライブラリで, 現在の Node ではこちらが使われています.
参考

- 作者: W.リチャードスティーヴンス,W.Richard Stevens,大木敦雄
- 出版社/メーカー: ピアソンエデュケーション
- 発売日: 2000/12
- メディア: 単行本
- 購入: 8人 クリック: 103回
- この商品を含むブログ (41件) を見る
- 今回最も参考にした本です. 通称 APUE.

UNIXネットワークプログラミング〈Vol.1〉ネットワークAPI:ソケットとXTI
<li><span class="hatena-asin-detail-label">作者:</span> <a href="http://d.hatena.ne.jp/keyword/W%2E%A5%EA%A5%C1%A5%E3%A1%BC%A5%C9%A5%B9%A5%C6%A5%A3%A1%BC%A5%F4%A5%F3%A5%B9" class="keyword">W.リチャードスティーヴンス</a>,<a href="http://d.hatena.ne.jp/keyword/W%2ERichard%20Stevens" class="keyword">W.Richard Stevens</a>,<a href="http://d.hatena.ne.jp/keyword/%BC%C4%C5%C4%CD%DB%B0%EC" class="keyword">篠田陽一</a></li>
<li><span class="hatena-asin-detail-label">出版社/メーカー:</span> <a href="http://d.hatena.ne.jp/keyword/%A5%D4%A5%A2%A5%BD%A5%F3%A5%A8%A5%C7%A5%E5%A5%B1%A1%BC%A5%B7%A5%E7%A5%F3" class="keyword">ピアソンエデュケーション</a></li>
<li><span class="hatena-asin-detail-label">発売日:</span> 1999/07</li>
<li><span class="hatena-asin-detail-label">メディア:</span> 単行本</li>
<li><span class="hatena-asin-detail-label">購入</span>: 8人 <span class="hatena-asin-detail-label">クリック</span>: 151回</li>
<li><a href="http://d.hatena.ne.jp/asin/4894712059" target="_blank">この商品を含むブログ (37件) を見る</a></li>
</ul>
- IO モデルの図はこちらを参考にしました
- no title
- 非同期 IO に関する記事ですが, IO モデルのマトリックスと, 各 IO モデルを説明した図が大変わかりやすいです.
まとめ
各 IO モデルについて概要を説明しました. ちょっと後半はだいぶ失速してしまっていますが…
ここからは各ライブラリの実装に目を通したり, あるいは冒頭の c10k の議論やサーバを考える場合はさらにスレッドやプロセスも組み合わせて考える必要があるので, そちらも掘り進めていけば良いかと思います.
*1:指定できるフラグの一覧は man を参照してください. システムコールは man のセクション 2 なので ‘man 2 open’ とすればよいはずです.