
Webエンジニアのための データベース技術[実践]入門
つまみぐい的に読んだ。気になったところのメモを。
B+ 木のインデックス
{
root: {
0: {
0: [0, 2, 3],
5: [4]
},
10: {
...
},
20: {
...
}
},
}- 適当な json だけど、こんなかんじの範囲を持つ多分木
- 葉にデータへのポインタを持っている
- 最終的に葉だけにポインタをもっているので、ある範囲のデータを SELECT する際にいちいち枝をうえにのぼらなくてよい
- ちなみに B- 木というのもあって、それは葉にもデータを持つらしい
- たとえば COUNT はインデックスへのアクセスだけに完結する
- そうでない場合は結局データへのランダムアクセスが必要。たくさんのデータを参照する場合は当然そのぶん遅くなる。
- mysql では UNIQUE 制約がついているカラムには自動的にインデックスがはられるが、そうすると一意性のチェックがはやいというのが理由
複合インデックス
- B+ 木のデータ構造をふまえて、複合インデックスの仕組みを想像する
- たとえば id と date の 2 カラムに複合インデックスをはるケース
- 結局のところ 2 つの型を組み合わせたタプルの比較関数が定義できれば良い
(123, '2013-01-01')のようなタプル- INSERT 時にはそれらを比較しインデックスに格納
- SELECT 時にもおなじ比較演算子で木を travarse
- 一番単純な比較関数の実装は、こんなかんじでタプルの前から順に比較していくというものだろう (各型の比較演算子がすでにあるものとする)
function cmp(a, b) {
if (a[0] == b[0]) return a[1] > b[1];
return a[0] > b[0];
}- 仮にこういう比較をしているとすると、複合インデックスのうしろにあるカラムだけで検索した際に、インデックスが効かないということがわかる
- (a, b) という複合インデックスだった場合、B+ 木のなかを a だけに注目してみてみると、a は必ず一定の順序で並んでいるはず。一方で b の順序は保証されていない
- 複合インデックスの後ろのカラムだけでインデックスを効かせて検索するには、比較関数をもっと比較関数を工夫する必要がある
- 複合インデックスのすべてのカラムが、木の中でソートされていれば良い
- たとえば 2 カラムの複合インデックスの場合。直感的には 2 次元座標系をイメージした比較関数をつくる
- 各ノードは中心座標をもっている
- よって第一〜第四象限にこの座標系をわけることができる。各象限を枝に対応させる
- これは 2 次元で座標系を 4 つにわけていく例だけど、次元・象限ともに拡張はできるはず
集約関数や ORDER BY
- 集約関数や ORDER BY はメモリを気にする必要があるが、考え方はふつうにアプリを書くときと同様
- たとえば集約関数。単純な SUM の場合は結果を入れる変数ひとつだけの領域をメモリ上に確保しておいてそこに足しこんでいくだけでいいので、データが増えても比較的性能が落ちにくい
- 一方でデータをメモリ上に展開しないとできないような計算の場合、メモリに載り切らなくなった時点でスワップして性能が一気に落ちるはず
- ORDER BY の場合、単純にはデータを全部メモリに乗せてソートするだけなので、やはり載り切らなくなると遅くなる
インデックスその他
- OR 検索のときなどはそれぞれに対してインデックス検索をしてマージする
- インデックスを検索するとアクセスすべきポインタのリストができあがる。OR 検索の際はそうやってできたリストの和 (union) で最終的なリストができて、それらに対してデータを参照しにいく
- 一般的に INSERT, DELETE 時にインデックスも操作しないといけないので、インデックスを貼ると追加削除処理は遅くなる
- innodb は更新をバッファしてたまったら適用という作戦で高速化している
- 基本的にインデックスの更新は、木の組み換えが必要なので並列化できない。よってその間は更新がロックする
- パーティショニングするとインデックスファイルを分けられるので、書き込み性能の劣化を抑えられる
- 一方でインデックスを並列更新するアルゴリズムもあるらしい
- インデックスが張ってあるキーを ALTER する場合。特に型を変えた場合などはインデックスも作りなおさないと行けないのですごく時間がかかりそうだし、ロックもしそう
バッファプールと REDO ログ
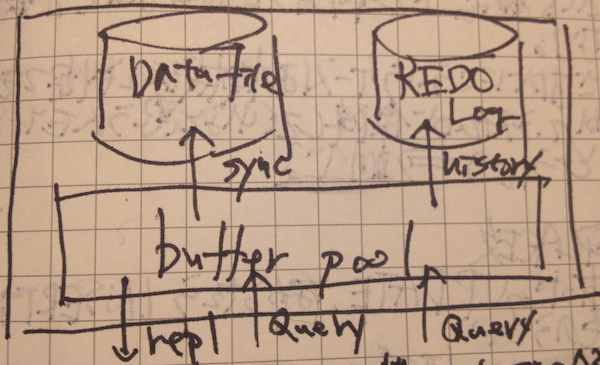
- トランザクションの実現、障害時の一貫性担保
- バッファプール
- メモリ上のデータ領域。まずはここが変わりあとでデータに落とされるという、まさにバッファ。透過的キャッシュなので、まだファイルに反映されていなくても、外からは更新されているようにみえる。
- REDO ログ
- バッファプールに発行されたクエリを記録するログ。ここに書き込まれた時点で更新クエリは完了とみなされる
- 障害時にバッファプールのデータが飛んだ場合でも REDO ログからクエリを再実行すれば障害直前の状態を復旧できる。mysql 起動時には REDO ログのチェックと適用を行っているらしい。
- REDO ログへの書き込みプロセスは 1 プロセスのみ。でもシーケンシャルライトだから普通にデータを毎回ランダムに書き込むより速い。
- これを踏まえてトランザクションの動きを想像すると、コミット前のトランザクション内のクエリはバッファプールにだけ適用して REDO ログにはまだ書かない。コミットしたら REDO ログに書き込み、ロールバックした場合はバッファプールの該当部分をクリアする。なんとなくはこんなかんじかなと思う。1 プロセスだとこれでいいけど、これだとコミット前の状態が別プロセスから見えてしまうからちょっと違いそう
- ひとつのクエリでも内容が複数の処理にわかれていることがある。データファイルとインデックスファイルの両方を更新する、データがファイル上では複数箇所に分かれているなど。トランザクションがないとこういう場合にデータ不整合がおきる
REPLACE 文
- レコードがあったら UPDATE、なかったら INSERT する構文
- SQL の標準ではなくて MySQL 独自。標準では MERGE というものがあるらしい
REPLACE table_name [INTO] (columns) VALUES (values)- ISNERT 文の単純な置換えで良い
- 内部では INSERT を試みてだめだったら DELETE INSERT をするらしい
INSERT ... ON DUPRICATE KEY UPDATE ...という書くと、INSERT できなかった場合に UPDATE する
データモデリング
おすすめされていた書籍。kindle 化されているのもはなかった