
ActiveRecord の接続管理の仕組み
ActiveRecord がデータベースとの接続をどう管理しているのかを調べたメモ。主に active_record/connection_adapters 以下の話。現時点での main ブランチの HEAD を参照した。
詰まったときに調べる箇所のあたりを付けられるよう全体観を持ちたいという目的だったので、細かい部分まで把握しきれていはおらず、ご了承ください。
ActiveRecord の使い方のおさらい
まず最初にユーザーとして、ActiveRecord でデータベースにクエリを発行する際の流れを簡単におさらいする。
まずデータベースの接続情報を database.yml に記載する。ここではメインとなる primay DB と animals DB の 2 つがあり、またそれぞれに primary (master) と replica があるとする (この例は Active Record で複数のデータベース利用 - Railsガイド から引用)。
production:
primary:
database: my_primary_database
username: root
password: <%= ENV['ROOT_PASSWORD'] %>
adapter: mysql2
primary_replica:
database: my_primary_database
username: root_readonly
password: <%= ENV['ROOT_READONLY_PASSWORD'] %>
adapter: mysql2
replica: true
animals:
database: my_animals_database
username: animals_root
password: <%= ENV['ANIMALS_ROOT_PASSWORD'] %>
adapter: mysql2
migrations_paths: db/animals_migrate
animals_replica:
database: my_animals_database
username: animals_readonly
password: <%= ENV['ANIMALS_READONLY_PASSWORD'] %>
adapter: mysql2
replica: true
これらのデータベースへの接続は抽象クラスで定義する。まずは ActiveRecord::Base を継承した ApplicationRecord で connects_to メソッドを使い primary への接続を記載する。それぞれ writing reading という role 名。なおここでの ApplicationRecord や writing reading といった命名は規約で定められている。
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary_replica }
end
animals DB への接続は別の抽象クラスを定義する。
class AnimalsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :animals, reading: :animals_replica }
end
これらの抽象クラスを継承したモデルクラスにて、それぞれの DB へクエリが発行される。
class Person < ApplicationRecord
end
class Dog < AnimalsRecord
end
Person.find(1) # primary DB へ SELECT
Dog.find(1) # animals DB へ SELECT
# 抽象クラスで connected_to を使うとモデルごとに接続先 role を切り替えられる。
ApplicationRecord.connected_to(role: :reading) do
Person.find(1) # primary DB の reading role を指定して SELECT
Dog.find(1) # こちらは animals DB の writing のまま
end
# Base.connected_to はすべての role を一括で切り替える
ActiveRecord::Base.connected_to(role: :reading) do
Person.find(1) # primary DB の reading role を指定して SELECT
Dog.find(1) # こちらも animals DB の reading role を指定子て SELECT
end
ActiveRecord::ConnectionAdapters::ConnectionHandler
まずは接続がどのように保持されているのかを中心に見ていく。
「おさらい」にあったように ActiveRecord は ApplicationRecord や AnimalsRecord などの抽象クラスごと、さらにその中の role ごとに別のデータベースを参照するようにできている (実際にはさらに shard という概念もあるが簡単のため今回は省略)。この 抽象クラス x role ごとに接続プールが別々に用意されている。ConnectionHandler とその周辺のクラスがこれらの接続プールを管理している。
全体像はこんな感じで、ツリー構造で各プールを保持している。
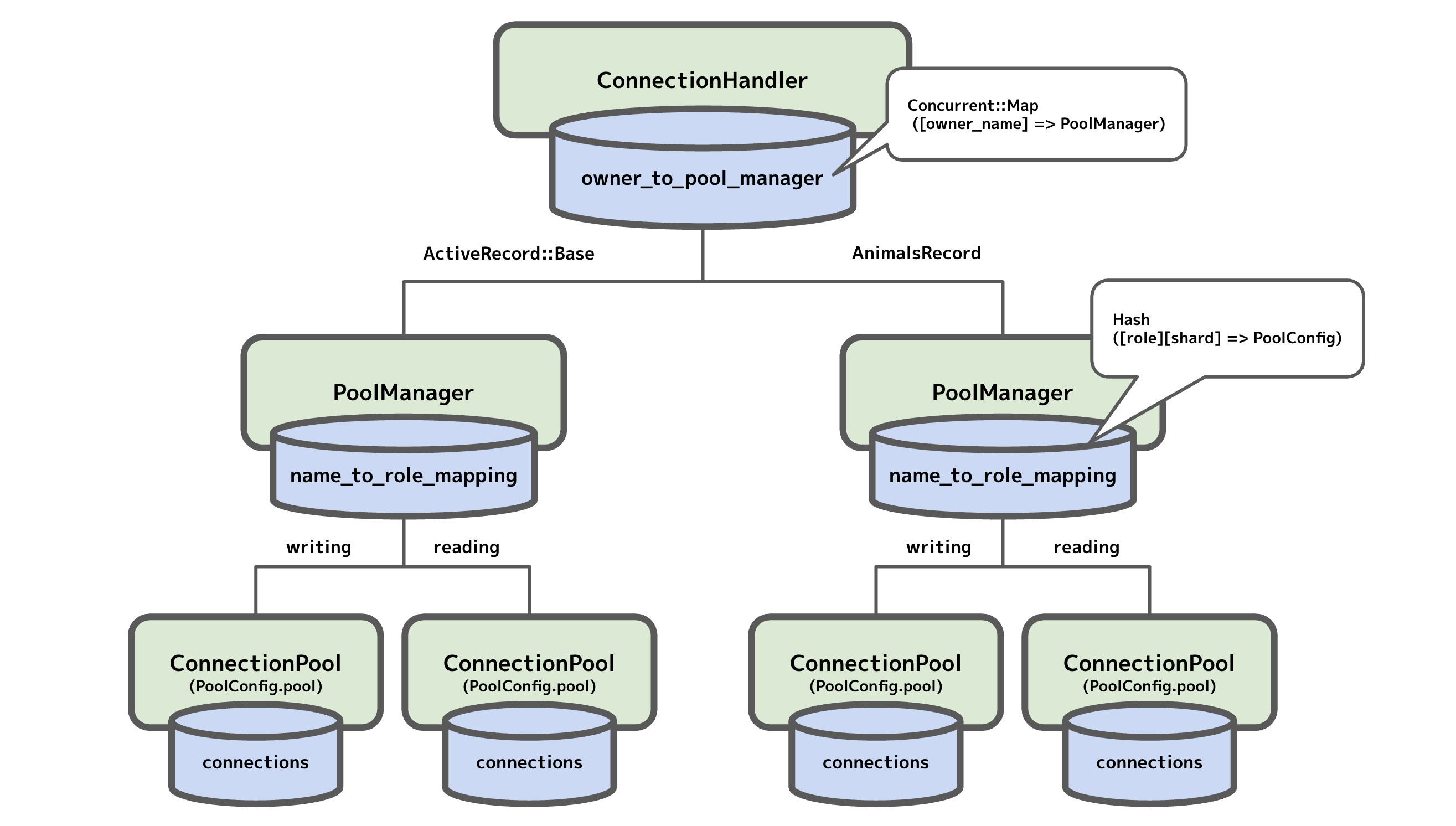
ConnectionHandler クラスは @owner_to_pool_manager という属性 を持ち、owner ごとに PoolManager のインスタンスを保持している。
ここでキーとなっている owner とは、そのモデルがどの DB に接続するかを定義している抽象クラスの名前で、今回の例だと ApplicationRecord や AnimalsRecord にあたる。ただし ApplicationRecord の場合は ActiveRecord::Base が 代わりに 使われる。またこの owner (owner_name) はコードの各所 (ConnectionHandling や PoolConfig)では connection_specification_name という名前の属性でアクセスできるようになっているので、こちらが正式名称かもしれない。
値となっている pool_manager とは、role と shard ごとに接続プールを保持しているクラス。name_to_role_mapping という Hash を属性として持っている。ここで @name_to_role_mapping[role][shard] = pool_config という形で接続プールを保持している。PoolConfig は名前の通りその接続プールとその設定を持っているクラスで、PoolConfig.pool 属性に接続プールの実態を保持している
ちなみにこのような構造になったのはおそらく 6.1 からで、それ以前は次のような構造だった。
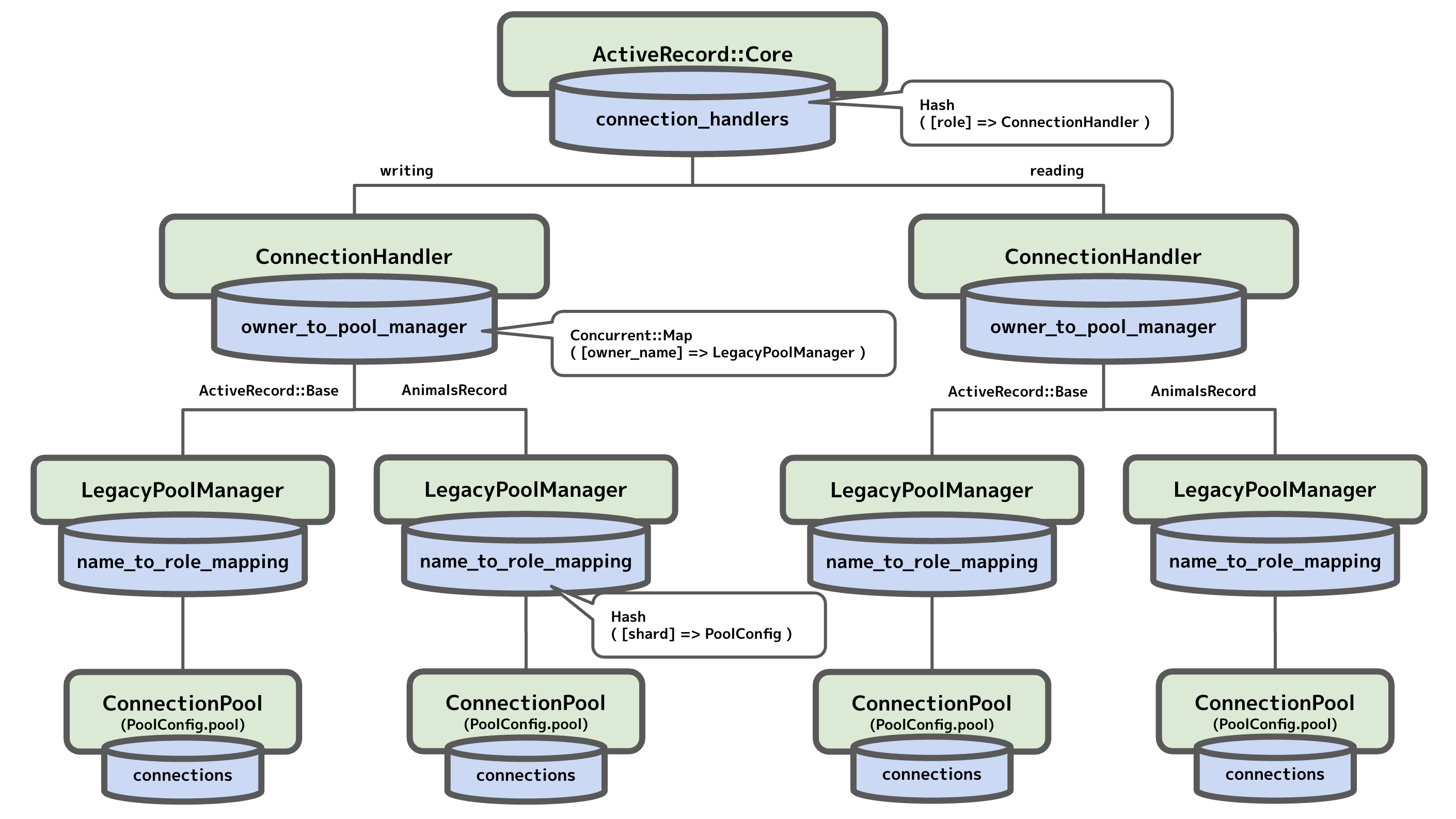
ConnectionHandler の上に connection_handlers というもう 1 階層があり、role はここで管理されていた。Ruby on Rails 6.1 リリースノート - Railsガイド にあるように、以前は role を切り替えるとすべてのデータベースで (ApplicationRecord, AnimalsRecord 共に) role が切り替わっていたのが、6.1 以降はデータベースごとに切り替えられるようになったらしい。確かにこのような、最上位の層で role を保持する持ち方だと全体が切り替わるようになってしまうのは納得できる。現時点では legacy_connection_handling というフラグで新旧のデータ構造が切り替わるようになっている (1, 2 など)。
ActiveRecord::ConnectionAdapters::ConnectionPool
このクラスが実際にデータベースへの接続を保持して、アプリケーションから接続を要求されるとそれを確保して渡したり、使用後に回収したりする役割を担っている。「コネクションプールを提供するライブラリ」と言われてぱっと想像するのがこのクラスだと思う。自分が過去に読んだところだと Go の sql.DB に近い部分。
全体像はこんな感じ。
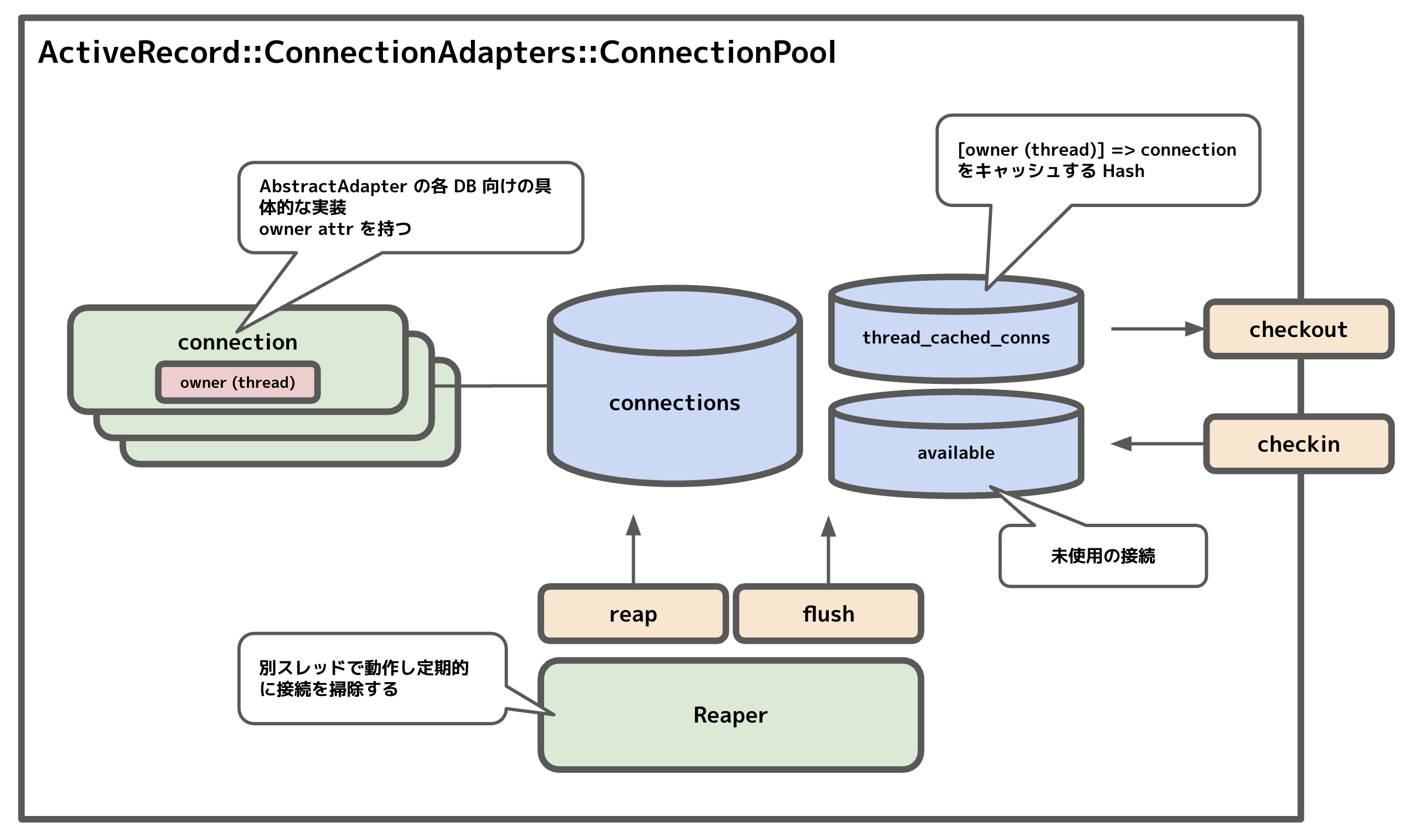
@connections という配列にすべての接続を保持している。このデータがこのクラスの中心。このうち利用されていない「フリー」な接続は @available にも入っている。@available は FIFO +アルファなキューらしい が詳しくは見ていない。
接続プールから接続を取り出すメソッドが checkout、反対に使い終わった接続を戻すメソッドが checkin。
checkout では まず available を確認しなければ新規接続を確立する。この時 database.yml などで指定する pool オプション の 数以上に接続ができないよう制御されている (pool のデフォルトは 5)。上限に達して新規接続を確立できない場合は、lost した接続の解放を試みたうえで、タイムアウトまで待つ。実際の接続確立処理は 各データベース実装に移譲 されている。
checkin では接続の利用を解放し available に登録する。その際に接続の 未使用時間のカウント @idle_since を更新 し、後述の一定時間利用のない接続を閉じる処理で利用する。
接続の実態を表すクラスは AbstractAdapter という抽象クラスを実装している各データベースのクラスで、例えば MySQL なら Mysql2Adapter などとなる。特徴的なのは owner という属性 を持っていることで、ここには その接続を使用している thread の識別子が入っている (なお fiber にも対応しているが以降は簡単のため thread のみを考えて記載)。ActiveRecord では接続はスレッドごとに 1 つになるように制御されている。thread_cached_conns という [thread (= owner)] => connection を保持するキャッシュがあり、接続を取得しようとした際はまずこのキャッシュを見て、なければプールから取得する ようになっている。また接続の状態が in_use? かどうかの判定は、この owner (= thread) 属性があるかどうかで行われて いて、接続を利用する際に in_use? = true だとエラーになるよう制御されている。
プールのいわゆる「お掃除」処理は Reaper というクラスが担当している。別スレッドて定期的 に reap と flush メソッドを呼び出している。reap は lost した接続、つまり checkin し忘れてそのスレッドも終了しているもの などを 解放する。flush は一定時間以上利用されていない接続を切断する。時間は idle_timeout というオプションで指定でき、デフォルトは 300 秒。reap とは異なり切断した接続は @connections からも削除される。
Life of a connection
ここまで CoonectionAdapters 以下で接続がどう保持されているかを中心に見てきたので、ここでは視点を変えて、接続の設定管理 - 接続確立 - 利用がの流れにそって処理を追ってみる。
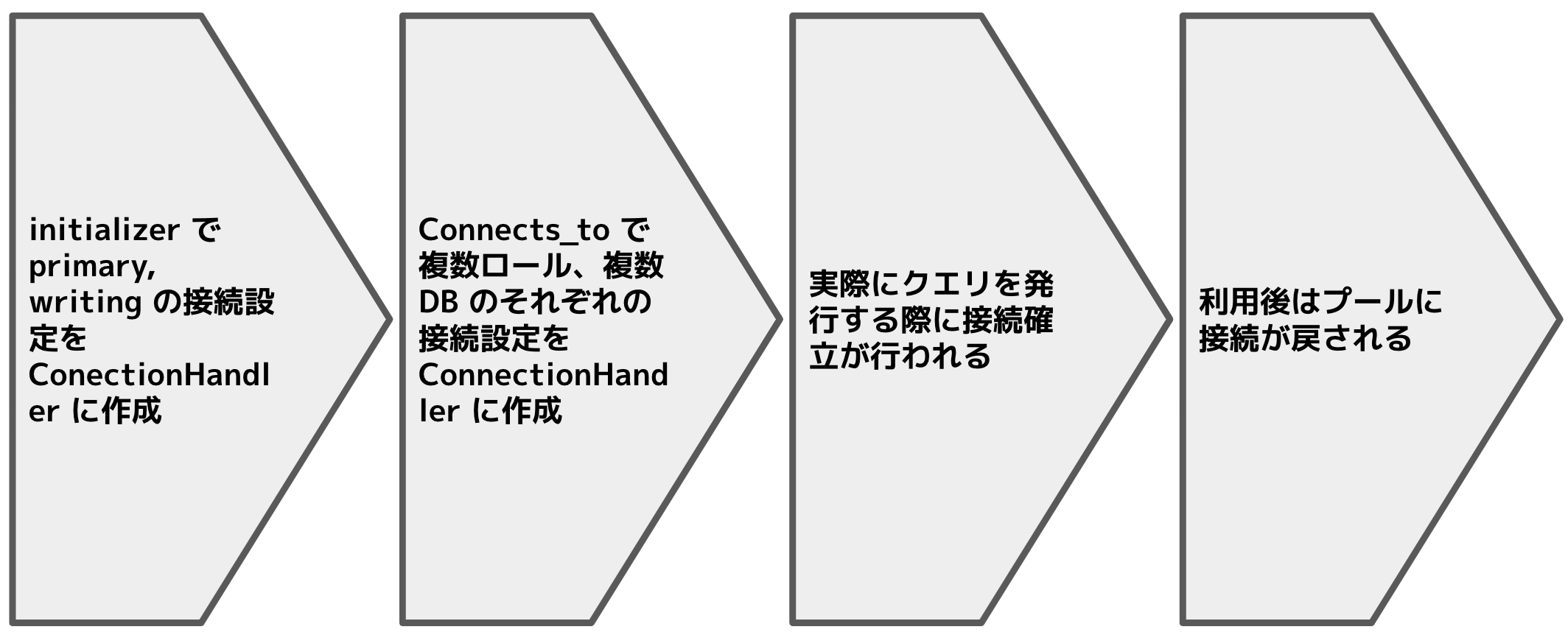
まず Rails 起動時に active_record.initialize_database が呼ばれる。ここでは 設定ファイル database.yml の読み込み をしたあとに引数無しで establish_connection を呼び出している。
establish_connection は ConnectionHandler 以下の必要なデータを設定していく処理で、その名前とは裏腹に実際の接続確立は行われない。
まず引数または設定ファイルから対応する接続情報を取得する。指定がない場合は 現在の環境 の設定中の最初のエントリが選択される。owner_name は ActiveRecord::Base 、role は :writing が選ばれる。こうして選択された接続情報、owner、role で ConnectionHandler.establish_connection を呼び出す。ConnectionHandler.establish_connection は前述の構造に沿ってデータを配置していくが、このとき同じ owner_name (= connection_specification_name) の接続データがすでにある場合、先にそれ削除し実接続があればそれも切断する。実際の接続確立はまだ行わない。
Rails アプリを テンプレート から作った直後などのシンプルな状態の場合、ここまでの active_record.initialize_database だけで必要な情報が ConnectionHandler に揃う。reading role 追加や複数 DB 対応をしている場合は、前述の例のように抽象クラスで connects_to で接続先をさらに指定することができる。その場合は connects_to が 渡されたデータベースや role について順に establish_connection を呼び出す ので、ここですべてのデータが ConnectionHandler 以下のツリー構造に揃うことになる。
実際の接続確立はデータベースに対して何らかの操作をするときに行われる。例えば適当なモデルから find などを呼び出すと、ConnectionHandling.connection で接続を取得しそれを利用する。このとき ConnectionHandling.connection はそのクラスの connection_specification_name, role で ConnectionPool.connection を 呼び出す。ConnectionPool.connection では @thread_chached_conn にあれば (= 同じスレッドで接続したことがあれば) それを、なければ checkout して接続を返す。つまり、それ以前に接続が無かった場合はこのタイミングで接続確立されることになる。
似たような役割のより便利インタフェースとして、ブロックを渡すとその前後で connection, relase_connection してくれる with_connection というメソッドも用意されている。またもちろん、ユーザー側で管理して生の checkout, checkin を使うこともできる。
ここまで見てきた ConnectionHandler のツリー構造を見るとわかるように、どのデータベースにクエリを発行するかは、その処理を度のクラス (モデル) から行うかに依存する。例えば今回の例だと AnimalsRecord を継承した Dog クラスは AnimalsRecord で指定された animals DB へクエリを発行するし、ActiveRecord::Base.connection は ApplicationRecord で指定された primary DB へクエリを発行する。仮に ActiveRecord::Base.establish_connection( animals DB への接続情報 ) などとすると @owner_to_pool_manager の ActiveRecord::Base のエントリが animals DB のものに置き換えられ、animals にクエリが飛ぶことになるので、通常はこのような使い方はしないはず。あくまでどの DB にクエリを飛ばすかはモデルで区別する設計になっている。
その中でどの role (と shard) にクエリを発行するかは database_selector という仕組みが自動でやってくれたりはするが、ActiveRecord::Base.connected_to でユーザーが手動で指定することもできる。これはあくまで role を指定するための仕組みで、前述のように構造上データベースを切り替えることはあまり想定されていないと思われる。
connected_to は前述の例のように ActiveRecord::Base.connected_to と呼び出すか、抽象クラス ApplicationRecord.connected_to と呼び出すかで挙動が変わる。複数のデータベースがあった場合、前者はすべての DB に対して role を指定するが、後者はその抽象クラスの子クラスの role だけを切り替える。これは ActiveRecord::Core の connected_to_stack という配列 で実現されている。connected_to を呼び出すと connected_to_stack に呼び出したクラスと role を記録する。その後接続取得時に current_role を参照する際、connected_to_stack の中身を見て role を判別している。Base クラスのエントリがあればそのロールを、そうでなく自分の親の抽象クラスのエントリがあればそれを使うといった具合。
misc
- Go の sql.DB で言う SetConnMaxLifetime のような、接続がプールに入って一定時間経ったら開放される仕組みは無さそうに見えた
- 接続プールのパラメータをどう設定するのが良いかは次の記事が参考になりそうだった
- Concurrency and Database Connections in Ruby with ActiveRecord | Heroku Dev Center
- サーバのワーカースレッド数や Sidekiq のワーカースレッド数にあわせる
- テストではデフォルトで 1 トランザクション中でデータベースを読み書きし、ケースの終了後にロールバックすることで高速化する仕組みが導入されている
- setup 時に ConnectionHandler 内を直接置き換えて、reading role への接続も writing へ飛ぶようにしている
- かつ lock_thread という仕組みで、メインスレッドが保有する DB 接続を他のスレッドからも使うよう強制している
- 並列したトランザクションをテストしたい場合など、この仕組をオフにしたいときは
use_transactional_testsというフラグ を オフにすればよい - 以前は use_transactional_fixtures というフラグ名だったらしい
- この transactional test の仕組みと、サードパーティのテストフレームワークがどのように協調しているかは、まだあまりよくわかっていない
- 例えば test-prof には前述の lock_thread の仕組みを使っている部分があったりする
参考
- rails/activerecord at main · rails/rails
- Active Record で複数のデータベース利用 - Railsガイド
- Rails テスティングガイド - Railsガイド
- Concurrency and Database Connections in Ruby with ActiveRecord | Heroku Dev Center
PR
