
読書メモ: Prometheus 実践ガイド

会社でも利用している Prometheus だが、なんとなくでしか使えていなかったのでキャッチアップのために読んだ。その目的なのでハンズオンの部分は割愛し、全体は 400 ページほどあるがさっと読むことができた。
Prometheus のアーキテクチャや PromQL の基礎が把握できて満足。前者は、Grafana の存在で可視化部分が疎になっているのはわかっていたが、Alert 部分も分かれていることや、リモートストレージを介して別 Prometheus や外部サービスと連動させやすいのは新鮮だった。後者について、もともと時系列データへのクエリは苦手だったが、基礎的なプリミティブ (Guage/Counter/Histogram/Summary の区分、label の概念、Instant/Range Vector) を押さえることで理解しやすくなったと思う。また PromQL に限らず抽象化すれば Cloud Monitoring など他製品とも共通の考え方なので、その点も有用だった。さわりだけだが TSDB のファイル構成にも触れられていて、シンプルながらパワフルな印象を持ち、面白そうだった。
以下読書メモ。
Part1:Prometheusと監視の基本
Chapter 1:Prometheusで監視を始めるには
- システム監視の基本
- 目的: サービスをユーザーに無事に届けるため = ダウンタイムの最小化
- 方式
- メトリクス
- システムの状態を数値化し時系列データとして扱う
- Prometheus, Zabbix, CloudWatch など
- ログ
- システムの状態を文字列として記録する
- 集計・比較しやすいメトリクスに対して、ログは詳細な情報が得られるがストレージ消費は多い
- Elasticsearch, Cloud Logging など
- トレーシング (分散トレーシング)
- ユーザーのリクエストにスコープを置き、各処理経路の所要時間を記録する
- 複数のコンポーネントをまたがるため、トレーシング ID という共通の ID で追跡する
- OpenTelemetry はその標準
- Jaeger, Zipkin, Datadog APM など
- メトリクス
- 監視の導入フロー
- サービスの正常・異常を定義
- i.e. コーポレートサイトがブラウザからアクセスできる、商品をカートにいれることができる、アップロードしたファイルが正常に転送される
- ユーザー側から導入する
- コンポーネントの CPU やメモリ使用率からではなく、「そのサービスが使えているのか」から始める
- ブラックボックス監視からホワイトボックス監視の順
- アラートを設定する
- 発報時にどんなアクションをするかを決め、通知レベルを分ける
- 継続的に調整、不要なアラートの削除をする
- 監視システム自体も監視する
- サービスの正常・異常を定義
- オブザーバビリティ
- クラウドネイティブな環境では、多数のコンポーネントが協調するため、問題の発生パターンを事前に予測するのが従来よりも難しい
- そのため各コンポーネントの状況が統一的な方法で記録され、それを事後に自由に取得できることが求められる
- こうした概念は Obserbability と名付けられている
Chapter 2:Prometheusの概要と基本的な使い方
- Prometheus とは
- CNCF Graduated Project
- すべてのデータを key-value のメトリクスとして扱う
- key はメトリクス名 + ラベル (
prometheus_build_info {instance="localhost:9090" })
- key はメトリクス名 + ラベル (
- PromQL
- メトリクスのクエリ言語
- エクスポーター
- 監視システム側に従属する統一的なクライアント (エージェント) ではなく、ミドルウェアや OS といった各監視対象ごとに従属するクライアント (エクスポーター) という考え方
- Pull 型モデルとサービスディスカバリ
- 監視サーバが各エクスポーターにメトリクスを問い合わせる Pull 型モデル
- 監視対象を中央で一元管理できる。例えば監視対象がメトリクスを送れなくなったという検知や、スケールインでなくなったノードのデータ破棄などが容易になる
- 伸縮するクラウドネイティブなインフラでは監視対象が動的に変わるため、サービスディスカバリが必要
- 監視サーバが各エクスポーターにメトリクスを問い合わせる Pull 型モデル
- アーキテクチャ
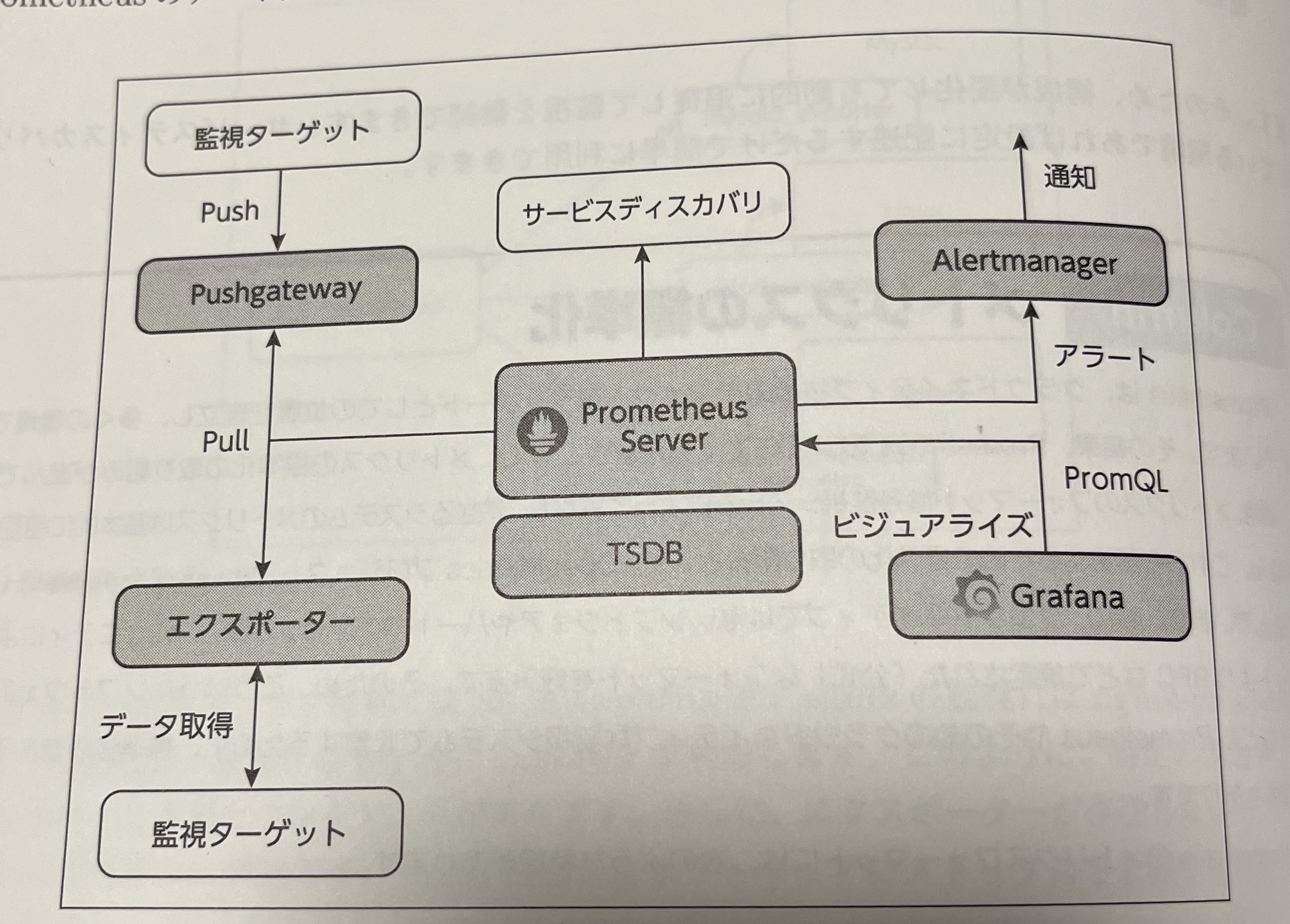
図2.5 Prometheus のアーキテクチャ より引用 - Prometheus Server + TSDB
- メトリクスの収集、保存、クエリを担当
- Exporter
- AlertManager
- Prometheus Server がアラートルールに則った PromQL を定期実行し、マッチするものがあれば AlertManager に送信する
- AlertManager はアラートのグルーピング、ラベル情報をもとにルーティングしたうえで通知を行う
- Grafana
- ビジュアライズ
- Pushgateway
- Push 型のメトリクス収集をカバーする。バッチ処理やイベントのような一時的な処理のメトリクス収集がユースケースになる
- 不得意なこと
- データの信頼性
- Pull したデータが正常かどうかを検知する仕組みは無い。例えばネットワークの問題でデータが欠損しても再取得する機能はない
- エクスポーターの管理コスト
- 種類が多く、コミュニティ、極端には個人がメンテナンスするものもある
- データの信頼性
- 構成ファイル
prometheus.ymlglobalでグローバル設定scrape_interval監視間隔scrape_timeout監視タイムアウトevaluation_intervalアラートルールの評価間隔- 評価時にはクエリを実行するため大量のルールがある場合は負荷がかかる
external_labels全体へのラベルを追加env: productionを全メトリクスにつけるといったユースケース
- その他リモートストレージの設定など
scrape_configsで監視対象を定義job_name監視対象の名前。監視対象ごとに Job という単位で管理metrics_pathエクスポーターのエンドポイント。デフォルトは/metricsschemehttp か httpsparamsクエリパラメータbasic_authベーシック認証- interval, timeout はグローバルの設定を上書きできる
alertingでアラートルールを定義alertmanagersAlertManager のエンドポイントを指定- 静的・動的に設定できる
alert_relabel_configsアラートルールのラベルを変更
rule_filesで外部ファイルからアラートルールを読み込む
- Topics: Prometheus のメトリクスフォーマットは Exposion Formats としてまとめられている
- これも参考にしつつオープンな標準として OpenMetrics がある
Chapter 3:監視ターゲットの検出とラベル操作
- サービスディスカバリーはクラウドインフラの API や k8s などに既にある外部のサービスディスカバリー機能を呼び出すのが基本
- それがない場合はカスタマイズしたディスカバリーシステムが必要になる
- Prometheus は監視対象の情報を label という形で保持している
- 監視対象のホストやパスなどもラベルとして表現されている
- 外部のサービスディスカバリーサービスから取得した対象の一覧に対して、さまざまな加工を行う必要がある。この操作を relabel (再ラベル) という
- 例えば gce のインスタンス情報を取得した場合、デフォルトでは ip としてプライベートアドレスが入っている。サブネット外の Prometheus から監視したい場合は別のフィールドにメタデータとして入っているパブリック ip を ip ラベルに置き換える
- そのほか、GCP など対象のサービス内のラベル表現を Prometheus 側の規則にそったラベルに置き換えたり、監視対象の絞り込みなども relabel の操作で実現する
Chapter 4:エクスポーターによるデータの収集
- HTTP API のエンドポイントを公開し、Prometheus server からの Pull に応じて監視対象のメトリクスを取得、所定のフォーマットに変換して返す役割
- 二つの動作モデル
- デーモン
- 監視対象とは別プロセスのデーモンとして動作する。Node exporter などはこのモデル
- プロキシ
- 監視対象が HTTP でメトリクスを公開している場合、Exporter が Prometheus との間にプロキシとして立つ。Prometheus server からは監視対象の URL を添えて Exporter にリクエスト、Exporter はそこに問い合わせ、メトリクスを返す
- 監視対象は Exporter 側には保持していない
- 監視対象が HTTP でメトリクスを公開している場合、Exporter が Prometheus との間にプロキシとして立つ。Prometheus server からは監視対象の URL を添えて Exporter にリクエスト、Exporter はそこに問い合わせ、メトリクスを返す
- デーモン
- メトリクスのフォーマット
- コメントとメトリクスデータから構成される
- メトリクスデータはメトリクスの key と value
- コメントには人間向けの純粋なコメントの他に、計算機向きのメトリクスの型情報も含まれている
# HELP go_goroutine Number of goroutines that currently exist.
# TYPE go_goroutine gauge
go_goroutine 38
Chapter 5:PromQLとメトリクス
メトリクスの種別
gauge: ある時点の値
counter: 累計値
histogram: 分布。各バケットの区切りが絶対値
le(less or equal) でバケットの区切りが表現されるprometheus_http_request_duration_seconds_bucket{handler="/",le="0.1"} 2 prometheus_http_request_duration_seconds_bucket{handler="/",le="0.2"} 3 prometheus_http_request_duration_seconds_bucket{handler="/",le="0.4"} 4 prometheus_http_request_duration_seconds_bucket{handler="/",le="1.0"} 5 prometheus_http_request_duration_seconds_bucket{handler="/",le="+Inf"} 5
summary: 分布。各バケットの区切りがパーセンタイル
prometheus_engine_query_duration_seconds{slice="inner_eval",quantile="0.5"} 0.001530686 prometheus_engine_query_duration_seconds{slice="inner_eval",quantile="0.9"} 0.001536674 prometheus_engine_query_duration_seconds{slice="inner_eval",quantile="0.99"} 0.001536674
被演算子のデータ型
Instant vector:ある一時点のデータ
up{instance="localhost:9090",job="prometheus} 1- 時間の指定がなければ最新のメトリクスが選ばれる
Range vector: ある期間のすべてのデータ
- データに加えてタイムスタンプを持つ
node_memory_MemFree_bytes{instance="localhost:9100",job="node_exporter"}[5m] 28323840 @1596386196.235 28323848 @1596386201.235 28323932 @1596386206.235 28384833 @1596386211.235 28329991 @1596386216.235- Scala
- 単純な数値
セレクタ
{job="prometheus"}といった、メトリクスから条件に一致するものをフィルタするための指定- セレクタがない場合は全件取得になる
# 全サーバのリクエスト数が返される prometheus_http_requests_total- matcher
=,!=,=~,!~- offset
offset 5mといった指定で、過去の時点データを取得する。範囲ではなく Instant vector を返す- range vector selector
[5m]といった指定で、過去の範囲データ Range vencor を取得する
演算子
算術演算子、比較二項演算子、論理演算子
集計演算
sum, min, max, avg, stddev, stdvar, count, count_values (count_if), bottomk, topk, quantile
grouping
- by: 指定したラベルでグルーピングして集計する
- without: 除外するラベルを指定し、残りのラベルすべてでグルーピングして集計する
# job ラベルごとの合計リクエスト数の集計例 sum(prometheus_http_requests_total) by (job)
関数
- rate, delta, sort など多くの種類がある
rate(node_cpu_seconds_total[ 5m ])
- rate, delta, sort など多くの種類がある
Chapter 6:ルールとアラート
- rule
- Prometheus server 側でクエリを定期実行する仕組み
- 定期実行のみを行う recording_rule
- アラートに対応する alert_rule
- promql と条件式、インターバル、付与するラベルなどを定義する
groups:
- name: example-alerts
rules:
- alert: HighMemoryUsage
expr: node_memory_Active_bytes / node_memory_MemTotal_bytes * 100 > 80
for: 5m
labels:
severity: critical
annotations:
summary: "High memory usage detected on instance {{ $labels.instance }}"
description: "Memory usage is above 80% for more than 5 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HighCPUUsage
expr: sum(rate(node_cpu_seconds_total{mode="system"}[1m])) by (instance) / count(node_cpu_seconds_total{mode="system"}[1m]) by (instance) * 100 > 90
for: 10m
labels:
severity: warning
annotations:
summary: "High CPU usage detected on instance {{ $labels.instance }}"
description: "CPU usage is above 90% for more than 10 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance down alert"
description: "Instance {{ $labels.instance }} is down for more than 1 minute."
- AlertManager
- 通知先を表現する receiver
- チーム別、レベル別などに分けるユースケース
- 指定したラベルにマッチすると送信する
- アラートをまとめる router
- 待ち時間やインターバルと共にグループ化するラベルを指定する
- 期間内のアラートを一つの通知にまとめられる
- 通知先を表現する receiver
Chapter 7:メトリクスを可視化する
Grafana の使い方の解説。一般的なグラフツールやクラウドインフラのモニタリングツールと概念はそう変わらないので割愛。
Part2:Prometheusの実践
Chapter 8:Kubernetesの監視
Kubernetes クラスタの監視や Prometheus operator について。必要な時に最新のチュートリアルを参照した方が良いので割愛。
Chapter 9:Prometheusのストレージ
ローカルストレージとリモートストレージ
- Prometheus server 足下のストレージ TSDB の形式でファイルを保存するローカル形式と、リモートの外部ストレージに連携する形式
TSDB
データ形式
- 時系列データを保持
- 一つのデータはサンプルデータと呼ばれる
- 2時間分ごとにブロックが分かれている
- チャンク内にはデータ本体と、そのブロックの期間等のメタデータ、インデックス
- クエリの際は、メタデータからブロックを、インデックスから対象のファイルを探してスキャンする
- 障害時の復旧のための WAL
- ヘッドブロックのデータはメモリ上に保持しているので、障害時は WAL から復旧する
- 一定以上古い期間のファイルはひとまとめにしていく
./data /01F01F5A3… # 2時間分ごとのブロック /chunk 00001 … index meta.json tombstones /01F5AAB8V… /01F5AAB8X… /chunks_head # 現在書き込み中のブロック(ヘッドブロック) /lock /queries.active /wal- データ量の見積もり
- 1 メトリクスあたりのデータサイズ x 秒間の取得メトリクス数 x 保持期間 = TSDB のデータサイズ という要領で見積もる
- 1 メトリクスあたりのデータサイズは 1, 2 byte という経験則で良い。残り二つの項目は設定から算出できる
リモートストレージ
- さまざまな外部サービスと接続できる
- read/write または write only の接続方式がある
- Prometheus はメトリクス収集に特化し、ストレージには書き込みのみ、可視化やアラートは外部システム側に任せる(あるいは別の Prometheus Server instance)という構成も可能になる
- read もする場合、通常は外部ストレージから一定期間のデータを全権取得し、Prometheus 側で PromQL で集計するという構成になる。Prometheus 側のメモリ使用量には注意が必要
- この意味でも可視化などを外部サービス側に任せる構成があり得てくる
- write にはバッファの大きさや並列数といったチューニングポイントがある。バッファが消費するメモリサイズや書き込みのレイテンシを鑑みながら調整する
Chapter 10:独自のメトリクスを公開する
- 方式
- Direct instrument
- 監視対象に Prometheus のインタフェースに従ったメトリクス取得のエンドポイントを直接実装する
- Exporter
- Exporter を実装する
- Direct instrument
- 実装時にはラベルのカーディナリティの低いメトリクスを作らないように注意する(本当に必要か検討する)
- 例えばメールアドレスごとのラベルなど
Chapter 11:実践的なPrometheusの活用
- 冗長化
- 複数の Prometheus server を起動するのがシンプル
- それぞれでストレージを別で持つ
- スクレイプ数やデータ量がサーバ数分増えてしまうが、シンプルなのがメリット
- お互いを監視させると良い
- Prometheus には冗長化のためのクラスタ化機能などはない
- AlertManager はクラスタ機能がある。複数起動し協調動作する
- 複数の Prometheus server を起動するのがシンプル
- 複数の Prometheus の連携
- 小型のサーバを複数展開するほうが運用しやすいことが多い
- サービスごとや環境ごとに別のサーバをたてる
- 並列の連携
- 複数の Prometheus が同一のリモートストレージに書き込む
- リモートストレージを参照しに Garafana などで可視化する
- ツリー型の連携
- 例えばデータセンター全体の監視で、フロアごとサーバのメトリクスを中央のサーバに集約する構成
- これをサポートする機能は Prometheus が提供している
- 中央(ツリーの上位)のサーバから Pull する federation と、下位のサーバから Push する Remote write receiver がある
- 別システムへの連携
- Managed Prometheus や Cloud Monitoring などへ転送する
- 一台であってもあり得る構成
- 小型のサーバを複数展開するほうが運用しやすいことが多い
- 配置場所
- 本番環境と同じ場所に構築する場合
- コスト削減、経路上のネットワークの影響が少ない、k8s operator を使えるといったメリットがある
- 分けるのは障害時の影響を分離でき、一般的には良い
- 本番環境と同じ場所に構築する場合
- メトリクス命名のコツ
- 上位のコンポーネントから順に並べる (nginx_system_memory_… など)
- メトリクス名は抽象化し、具体性の高い情報はラベルにする
Chapter 12:Prometheusの周辺ツール
- PushGateway
- バッチなど短命なジョブのメトリクス収集
- VictoriaMetrics
- Prometheus 専用に作られたリモートストレージ
- Prometheus Loki
- Prometheus と親和性の高いログツール