
読書メモ: Stream Processing with Apache Flink

会社で運用し始めたので、キャッチアップのために読んだ。そしてその目的にはぴったりの本だった。Apache Flink の専門書ではあるが、ストリーミング処理やその周辺のログ基盤技術についてあまり馴染みのない・片手間で対応してきたが体型的には把握できていないエンジニアが素早くキャッチアップするのに、コンパクトにまとまっていることもあり最適だった。一方で全体的に深入りはしていないので、すでにこの分野や Flink そのものに習熟しているエンジニアには物足りないかもしれない。
1 から 3 章は Flink に限らないストリーミング処理一般の概念や設計思想の説明で、特に興味深かった。解決したい要件に対して、既存のアプローチ(バッチ中心の構成やラムダアーキテクチャなど)との比較から始まり、ストリーミング処理独自のチャレンジ、トレードオフの紹介などがまとまっている。
また例えば watermark の仕組みが興味深い。分散システムの一般的な特性だが、ネットワーク越しの外部からのデータが確実にタイムリーに到着するとは仮定できないため、できるだけデータの到着を長く待った方がより正確な計算ができる。一方で無限に待つことはできず、あまりに長く待つとレイテンシが悪化するという、正確性とレイテンシのトレードオフの関係がある。これを調停するのが watermark という仕組みで、その時点でデータは確定しているとみなす閾値、= どの程度待つか、を定めている。
他には、例えば障害時に計算途中から処理を再開するための checkpoint という中間データを永続化する仕組みがあるが、全体のレイテンシと障害時の復旧速度はトレードオフの関係にあり、(他にもチューニングポイントはいくつかあるが) checkpoint 取得頻度というパラメータでそれを調整できるようになっている。また連鎖するオペレーターで上流から checkpoint を取得するためのマーク (checkpoint barrier) を流すことで全体の整合性が取られるというアプローチも綺麗だ。
4 章以降は Flink の具体的なセットアップやアプリケーションの実装の説明となり、基本的には流し読み、必要になってから参照しに戻れるよう頭にインデックスを作るイメージで読んだ。次は実際に手を動かしたり、運用している仕組みの実態を把握していったりしたいと思う。
以降は読書メモ。
1. Introduction to Stateful Stream Processing
- A Distributed stream processor
- Stateful Stream Processing Application を実装できる
- 2014 に Apache の incubating project 入り
- 従来型のデータ基盤
- 従来のデータ基盤は Transactional processing と Analytical processing に分かれている考え方だった
- Transactional
- いわゆる OLTP の DBMS に各アプリケーションがアクセスする形式
- データ量が増加した場合の最近のアプローチはマイクロサービスで、分割することでデータストア1つあたりの規模を抑える
- Analytical
- Transactional DBMS 上のデータは通常 (マイクロサービス構成では特に) 分散しているので、それを一箇所のデータウェアハウスに集約する
- この集約処理は ETL と呼ばれる
- データの抽出、変換、バリデーション、正規化、エンコーディング、重複排除などを行う
- 一般的に ETL はバッチ処理で、ビジネス要件に応じて実行頻度を高めるには相応のコストや技術が必要とされる
- データウェアハウスにインポートされたデータの利用方法は、定期実行クエリとアドホッククエリに分類できる
- 今日ではデータストアとしては HDFS、S3、HBase などが、その上で動く処理エンジンとして Hive, Drill, Impalla といった SQL-on-Hadoop エンジンが使われることが多い
- Stateful Stream Processing
- すべてのデータは「継続するイベントのストリーム」と抽象化することができる。Stateful Stream Processing はこのイベントストリームを処理し多様なユースケースに対応できるデザインパターン
- 大まかな仕組み
- イベントストリームは単にその時点のレコードだけを処理するのではなく、なんらかの状態 (中間データ) を参照する必要がある
- 各所からアクセスできるデータストアに中間データを保持し、アプリケーションがイベントを受け取った際にそのデータを読み書きする
- Flink は状態をローカルのメモリに保持する。また Flink は分散システムなので、状態を定期的にチェックポイントとして外部ストレージに冗長化し、障害に備えている
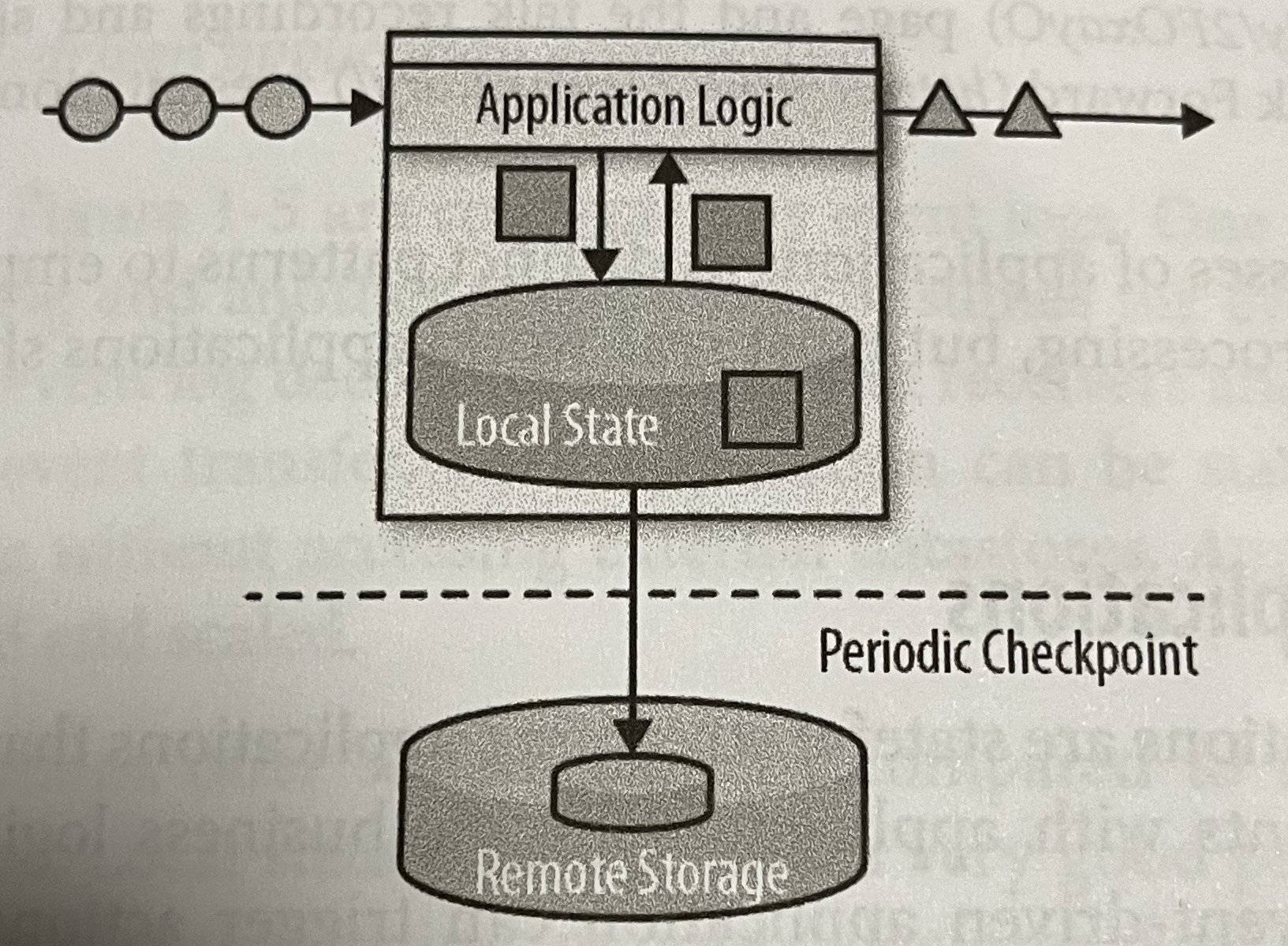
Figure 1-4. A stateful streaming application より引用
- イベントの受け取りにはよく Kafka 等の Event log system が使われる
- イベントストリームを追記のみで immutable な Event Log として扱う
- この特性は過去の特定の時点からの「リプレイ」を可能にするので、耐障害性が高い。またバグ修正、マイグレーション、AB テストも容易になる
- イベントストリームは単にその時点のレコードだけを処理するのではなく、なんらかの状態 (中間データ) を参照する必要がある
- 代表的なユースケース
- Event-Driven Applications
- イベントのストリームをトリガーに動作するアプリケーション。一つのアプリケーションは別のアプリケーションが発したイベントを Consume する (= Event-Driven アプリケーションが数珠繫ぎになっている) 構成もある
- Real-time recommendation, Pattern detection (Fraund detection), Anomaly detection などが代表的なユースケース
- Transaction なシステム、またはマイクロサービス、と比較すると、通信手段が REST API から Event-log に、データストアが RDB からローカルのステートに変わっている
- 状態をより近くに持っているのでパフォーマンスに有利で、またスケールや耐障害性の担保を Stream Processor 側に任せることができるのがメリット
- Data Pipelines
- 一般的にシステム全体の中で、パフォーマンス要件のためデータはいろいろなデータストアに分散する
- これらのデータストア間の同期は、ナイーブには定期的な ETL で行われるが、レイテンシが要件に合わなくなることも多い
- その場合 Stream Processor がその同期を担うことでレイテンシを大幅に下げられる
- データソースの変更をイベントとして受け取り、Consumer のデータストアに (必要に応じて正規化などを行った上で) 挿入する
- Stream Processor には多様なデータ Source, Sink への対応が求められる
- Streaming Analytics
- 従来のデータ分析は定期的な ETL、数時間から数日のレイテンシ、に頼っていたが、Stream Processor に置き換えることでほぼリアルタイムの分析が可能になる
- 例えばモバイルネットワーク回線品質のモニタリング、モバイルアプリのユーザー行動分析、消費者のリアルタイムデータのアドホック分析などが可能になる
- 隠れたメリットとしては、従来構成では複数のコンポーネント (ETL プロセス、データストア、データプロセッサー、スケジューラーなど) が必要だったが、Stream Processor によって一つのコンポーネントで済むようになる
- 従来のデータ分析は定期的な ETL、数時間から数日のレイテンシ、に頼っていたが、Stream Processor に置き換えることでほぼリアルタイムの分析が可能になる
- Event-Driven Applications
- Stream Processor の歴史
- 第1世代 (Lambda Architecture) (2011 年頃)
- Stream Processor はレイテンシの改善 (milliseconds レベル) を主目的として、反面正確性と一貫性は保障していなかった。またイベントは more-than-once で処理されていた
- Lambda Architecture は従来の Batch Layer (正確だが高レイテンシ) と Speed Layer (不正確だが低レイテンシ) を並列させるというもの
- 主なデメリット
- 意味的に同じ処理を別の API 向けに 2 回実装する必要がある
- Speed Layer の結果が概算値のみ
- セットアップとメンテナンスが複雑
- 第2世代 (2013 年頃)
- 対障害性と exactly-once を保障し、よりシンプルな API を提供するが、レイテンシは秒レベルまで落ちてしまった
- 第3世代 (2015 年頃)
- イベントが届いたタイミングと順序に依存する問題を解決し、またスループットとレイテンシを両立させるようになった
- この時点で Lambda Architecture は不要になり Stream Processor に 1 本化できるようになった
- Flink は第 3 世代のプロダクト
- 第1世代 (Lambda Architecture) (2011 年頃)
2. Stream Processing Fundamentals
- Introduction of Dataflow Programming
- 有向グラフで表現される処理の流れ
- ノードがオペレータでエッジがデータの依存関係を表し、一つ以上の source と sink がある
- ハッシュタグをカウントする例。これはハイレベルな処理の抽象化なので「ロジカル」と呼ばれる

Figure 2-1. A logical dataflow graph to continuously count hashtags より引用
- 一方で実際に各ノードで処理されるグラフは「フィジカル」と呼ばれる
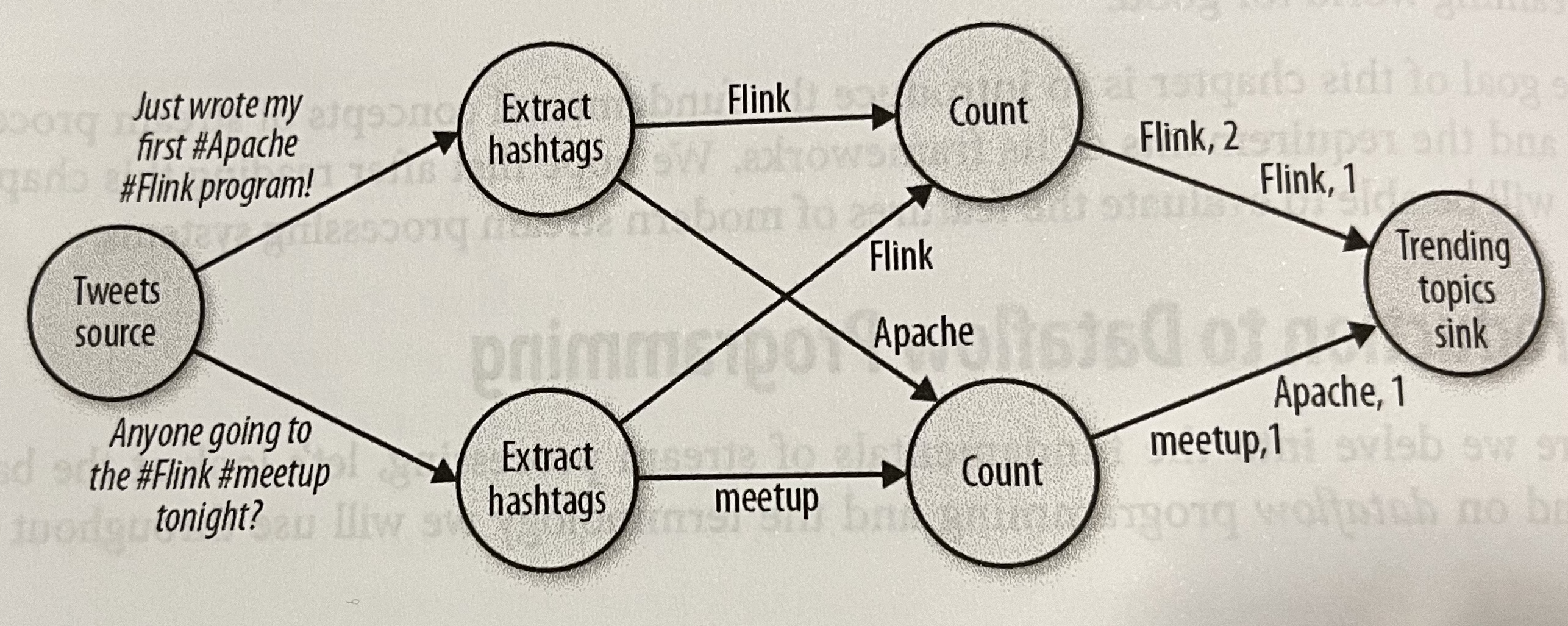
Figure 2-2. A physical dataflow plan for counting hashtags より引用
- Data Parallelism と Task Parallelism
- 前者はデータを分割し、同じ処理を異なるデータのサブセットに対して繰り返すこと
- 後者は異なる処理を並列に動かすこと
- Data exchange strategy
- Forward
- 単純に次のタスクに全データを渡す。同じ何度ならネットワークコストがかからない
- Broadcast
- 次の並列タスク全てに全データを渡す。コストが高い
- Key based
- キーに合致するものは必ず同じタスクに処理されるよう保障
- Random
- ランダムに均等に分散させる
- Forward
- ストリームの並列処理
Data stream: 区切りのないイベントのシーケンス- Latency と Thoughtput
- Latency
- イベントが登録されてから最終成果が出来上がるまで
- 低 Latency が Stream Processor の最大の特徴であり従来のバッチ処理との大きな違い
- Throughout
- 単位時間あたりの処理量
- 処理できる最大スループットを超えた入力がある状況を backpressure と呼ぶ
- レイテンシが下がるとスループットは上がる関係にある
- Latency
- Operations
- ステートレスなオペレーションはそれぞれ独立なので並列化や障害時のリトライがしやすいが、ステートフルな場合は簡単ではない。以下でケースごとに詳細を見ていく
- データの挿入 source と送出 sink (ステートレス)
- 多様なフォーマットへの対応する
- Transformation operations (ステートレス)
- 入力を変換し出力する単純な操作
- 複数の入出力先に対応する
- Rolling aggregations (ステートフル)
- sum, min, max といった集約を行う操作で、ステートフル
- 集約関数は結合的かつ可換的である必要がある。そうでなければすべてのデータ履歴を保持する必要があるので
- Window operations (ステートフル)
- transformation や aggrigation は単一のイベントに対する処理だが、複数のデータに対する処理も必要
- Window は無限のストリームから有限のデータセットを生成する
- 1 つの bucket にどのようにデータを入れるかを定める window policy と、どのタイミングで bucket のデータを評価 (計算) するかの trigger policy がある
- Tumbling window
- 一定のイベント (カウント、時間ごと等) をオーバーラップしないで bucket に入れる
- bucket がいっぱいになった時点 (指定したカウントに達したか、指定した時間に達した時点) で計算を行う
- Sliding window
- 一定のイベントをオーバーラップさせて bucket に入れる
- Length (1 bucket あたりのイベント数) と Slide (次の bucket を作成するタイミング) を指定する

Figure 2-8. Sliding count-based window with a length of four events and a slide of three events より引用
- Session window
- イベントの間隔が一定以上空いた場合に bucket を閉じる。この間隔を session gap と呼ぶ
- ユーザー行動分析等現実のユースケースに対して有用
- Parallel windows
- 例えばデバイス ID でイベントを分けてから、それぞれに対して並列に独立して Window 操作を行う
- Time semantics
- 正しい順序ではなく届いたイベントの処理や、過去データのリプレイの処理に必要な概念
- 例えば地下鉄乗車中のゲームプレイ。ネットワークが不通の区間に入るとイベントがローカルにバッファリングされ、復旧した際に一括送信される。このとき、イベントを受け取った時刻 (Processing Time) で処理するよりも、イベントの実際の時刻 (Event Time) で処理できたほうがよい
- Event Time をもとにした処理で、ネットワーク品質に依存せず、決定論的にストリームを処理できる。この性質は過去データのリプレイにも有効
- 遅延して届くイベントをどれだけ待つかは、確率論的で簡単に決めることはできない。その調整弁として Watermarks がある。Watermarks は仮にすべてのイベントを処理しきった時刻を表す。短くするとレイテンシは下がるが誤差が増えるというトレードオフがある
- アプリケーションによっては Watermarks を超えて遅延したイベントを適切に処理する必要がある (ログに残す、再計算するなど)
- 正確な結果が不要な場合などは Processing Time を使うこともある。Event Time に比べてレイテンシが低い
- State and Consistency Models
- 状態管理の難しさ
- State management
- 複数のオペレーターからの並行したアクセスの制御も必要
- State partitioning
- State recovery
- 最も大きなチャレンジ
- State management
- Task failures
- イベントを受診してローカルバッファに入れる、イベントを読み取り内部状態を更新する、計算結果を送信する。どの時点での障害からも、一貫した内部状態への復旧を保証したい
- 従来のバッチ構成だと毎実行がステートレスなのでこの問題は無い
- ここでは内部状態の一貫性の保証について扱う。出力の一貫性は扱わない。sink 先がトランザクションに対応しているかどうか次第なので。
- 保証の種類
- At-most-once
- no-guaranteeと同じ。レイテンシが重要で正確さは不要な場合には取りうるオプション
- At-least-once
- イベントのロストはなく、重複はある
- 冗長化されたイベントログのリプレイや、イベント受信時の acknowledge (ack されて初めて送信側はそのイベントを discard できる)といった実現方法がある
- Exactly-once
- 最も厳密で実現が難しい保証
- At-least-once 同様のリプレイと、その際にどこまでが内部状態に反映されたかの考慮が行われる
- transactional な状態更新がひとつのアプローチだが、パフォーマンスのオーバーヘッドが大きい
- 他にはより軽量な sharpshooting の仕組みを使うアプローチがあり、Flink はこちらを採用している
- End-to-end exactly-once
- オペレーターごとでなく、パイプライン全体での保証
- 一般的には個々のオペレーターの保証レベルより、全体の保証レベルは弱いものになる。ただし各オペレーターが冪等な場合、at-least-once 保証から exactly-once が実現できたりする
- At-most-once
- イベントを受診してローカルバッファに入れる、イベントを読み取り内部状態を更新する、計算結果を送信する。どの時点での障害からも、一貫した内部状態への復旧を保証したい
- 状態管理の難しさ
3. The Architecture of Apache Flink
- System architecture
- 一般的な分散システムの難しさ - コンピューティング資源のアロケーションと管理、プロセス間の調停、冗長で高可用性のあるストレージ、障害復旧 - のうち一部は、k8s, HDFS や S3, ZooKeeper といった既存のソリューションに任せている
- コンポーネント
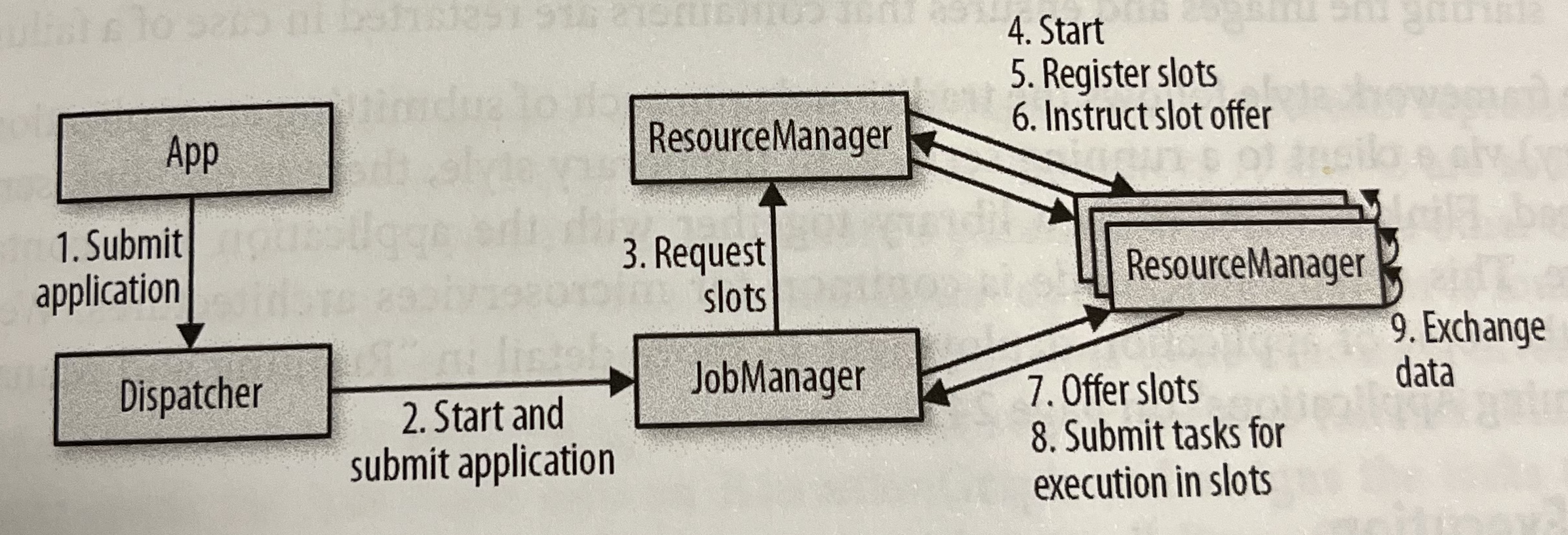
Figure 3-1. Application submission and component interactions より引用 - JobManager
- アプリケーションごとのマスタープロセス
- アプリケーションを JobGraph (logical dataflow graph) として受け取り、ExecutionGraph (physical) を組み立てる
- 必要なクラスやライブラリなどがバンドルされた JAR も必要
- ResourceManager に必要な資源 (TaskManager slots) を要求し、満たされたらデプロイ
- アプリケーションの実行中は調停が必要なアクション(障害復旧のためのチェックポイント関連など)に責任を持つ
- ResourceManager
- TaskManager slots という単位でリソースを管理
- バックエンドは k8s, YARN, Mesos, standalone cluster など
- TaskManager
- いわゆるワーカープロセス。ひとつの TaskManager に複数の slot がある
- Dispatcher
- アプリケーションを登録する REST API や Dashboard の提供
- Application deployment
- 複数のアプリケーションを受け付けることができる Framework style と、特定のアプリケーションごとバンドルされている Library style がある
- Task execution
- 一つの JobGraph を複数の TaskManager slot に並列に割り当てられる
- ひとつの slot には複数のオペレーターが入る。slot 間の通信が少ない方がパフォーマンスに有利
- 各 slot はスレッドで実装されている。パフォーマンスとスレッド感の独立性(極端には TaskManager ごとに 1 slot にすると独立性は高まる)はトレードオフの関係にある
- Highly available setup
- 特に JobManager の冗長化について
- JobManager は JobGraph や JAR などの必要情報を外部ストレージに、そのポインタやメタデータを Zookeeper に保存する
- 再起動した際や待機系に切り替わった際は Zookeeper の情報を元にクラスタを復旧、再開する
- Data transfer in Flink
- TaskManager にはデータを受け取る Receiver と送る Sender があり、それぞれにはバッファがある
- それぞれ送受信信先の Receiver, Sender ごとにバッファがわかれている
- 同じノードの TaskManager 同士はメモリを介してネットワークを経ずにデータをやり取りする
- ネットワークを介す場合、ノード間で永続的な TCP 接続が張られ、その接続内では各 TaskManager の通信が多重化されている
- Credit-Based Flow Control
- 送信バッファと受信バッファの余裕に応じて適切な送信量を調整する仕組み
- receiver は sender に受入可能な量を credit として伝える
- sender は credit の範囲で必要なだけデータを送る。その際に自身の backlog (バッファ内にあり送信準備完了しているデータの量) も receiver に伝える
- receiver は sender の backlog も考慮して credit を調整する
- Task Chaining
- 同じ並列性と local forward で繋がれているオペレータを一つのオペレータにまとめて、タスク授受のオーバーヘッドを減らす
- ただし 1 つのオペレーターの処理が重いなど、あえて chain しないほうが有利なケースもある
- TaskManager にはデータを受け取る Receiver と送る Sender があり、それぞれにはバッファがある
- Event-time processing
- Event-time で動作させる場合、各データは必ず timestamp を持つ必要がある
- イベントが発生した時刻が一般的だが、アプリケーションによって定義は変わって良い。ストリームプロセッサーからすると、とにかくイベントはこの timestamp 順に並んでいるとみなして処理する
- Watermarks は単調増加する event-time の時計として機能する
- Watermark 以前の timestamp を持つイベントは Late records と呼ばれ、そのハンドリングは後述
- オペレータは内部に Timer サービスを持っており、そこにコールバックを (例えば Window 処理で集計を行う処理のコールバックを) 登録する
- Timer は Watermark を受け取り、それが登録されているコールバックの Event time より進んでいれば、そのコールバックを実行する。その後 Watermark を下流に投げる
- Watermak は上流のパーティション事に保持している。Timer 内部の Event-time はそれらの最小値を参照し、下流にもそれを Watermark として伝える
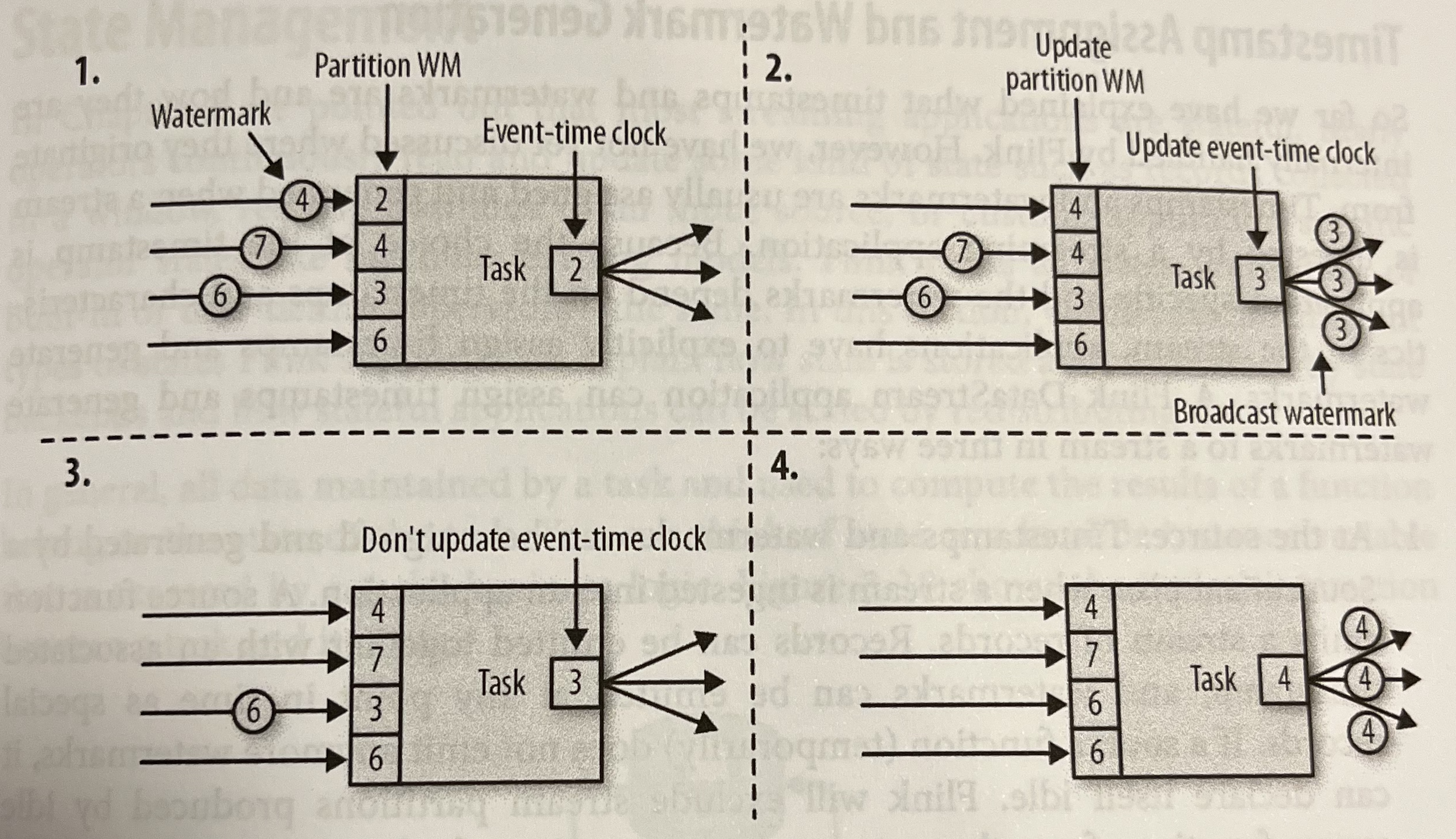
Figure 3-9. Updating the event time of task with watermarks より引用 - この設計では、一部の Watermark が著しく遅れたり idle 状態になるとそれ以降のオペレーターに悪影響が出る
- 一定以上 idle なパーティションは Watermark のハンドリング時に除外するといった対策がされている。詳しくは後述
- Timestamp と Watermark は基本的にはアプリケーションの Srouce で生成され、下流のオペレーターへ流れていく
- AssignerWithPeriodicWatermarks, AssignerWithPunctuatedWatermarks といったユーザーがカスタムできるインタフェースもある。その場合でも Source の近くでそれを行うことが推奨されている
- Event-time で動作させる場合、各データは必ず timestamp を持つ必要がある
- State management
- Flinkでは状態はオペレーターに紐づく
- Operator state
- ひとつのオペレーター単位のスコープのデータ
- Keyed state
- input のキーによってアクセスできるデータ
- state backend
- メモリまたは RocksDB
- 高速な前者に対して、大きいサイズにも対応できるのは後者
- スケールイン、アウトの際は、データの種類に応じて、リパーテイション、コピーなどを行う
- Checkpoints, Savepoints, and state recovery
- Consistent checkpoints
- ある時点での内部状態を外部ストレージに永続化する
- 障害時はアプリケーション全体をリセットし、最新のチェックポイントから状態を復旧、そのチェックポイントが取られた時点まで Source を巻き戻し resume する
- アプリケーションの各タスクから見るとこれで exactly-once が実現されている
- Source がリプレイに対応していないと実現できない
- Sink には障害復旧前後で同じデータが二度流されることになる。そのトランザクションや冪等性を持った実装などでハンドリングする必要がある
- チェックポイントの取得
- Stop-the-world: すべてのタスクを停止し、処理中のものがすべて完了するのを待ってからチェックポイントを取得。その後処理を再開する
- Chandy-Lamport algorithm: タスク実行を継続しながら取得できる。Flink はこれを採用している
- checkpoint barrier という watermark のような印を JobManager source から sink に流す
- Source は barrier を受け取るとその時点の状態をチェックポイントに書き込む。また JobManager に Ack を送り、下流に barrier を流す
- 各オペレータはすべての入力からの barrier が揃うまで待ち、揃ってからチェックポイントに書き込み、下流に barrier を流す。最初に Source A から barrier を受け取り、Source B の barrier を待っている間、Source A からの入力は処理せずバッファリングする
- Sink は同様に barrier を受け取り、チェックポイントを書き込んだ後 JobManager に Ack を伝える
- レイテンシを下げるための工夫も行われている
- チェックポイントバックエンドによっては、状態をローカルコピーしている間だけタスクを止めるが、コピーをリモートストレージに書き込む処理は非同期に行うものもある (FileSystem, RocksDB など)
- RocksDB は incremental checkpointing をサポートしている
- exactly-once ではなく at-least-once が許容できる場合、複数 source の barrier が揃うのを待つ間にバッファリングせずに処理を継続する
- Savepoints
- Checkpointsと同じ仕組みでアプリケーション全体の状態を保存、後ほどそこから resume できる
- ある状態から再生してデバッグしたり、別クラスタへの移行、クラスタバージョン更新といったユースケースで有用
- Consistent checkpoints
4. Setting Up a Development Environment for Apache Flink
https://github.com/streaming-with-flink/examples-scala のセットアップの説明。
5. The DataStream API (v1.7)
基本的な構成
実行環境の取得
val env = StreamExecutionEnvironment.getExecutionEnvironment- local か remote かを状況に応じて返す
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)- event-time モードに設定
入力ストリームの読み込み
val readings: DataStream[SensorReading] = env.addSource(new SensorSource).assignTimestampsAndWatermarks(new SensorTimeAssigner)- SensorSource はランダムなセンサーデータを生成する
- その後タイムスタンプと watermark を付与
変換
- map() 関数で華氏から摂氏に変換
- KeyBy() で id でグルーピング
- timeWindow() で 1 秒間のウィンドウを作成
- apply() でユーザー定義関数を適用し平均を計算
val avgTemp: DataStream[SensorReading] = readings .map( r => SensorReading(r.id, r.timestamp, (r.temperature - 32) * (5.0 / 9.0)) ) .keyBy(_.id) .timeWindow(Time.seconds(1)) .apply(new TemperatureAverager)- 出力
- 今回は
avgTemp: DataStream[SensorReading]に結果が保持され、標準出力に出力される - 典型的には Apache Kafka, Filesystem, Database などの Sink に出力される
- 実行
env.execute("Compute average sensor temperature")を呼び出した時点で始めて実行がトリガーされる- それまでの API 呼び出しは実行計画の作成までで、実際の変換処理は遅延実行となる
- 実行計画は JobGraph に変換され、JobManager に送信される
/** Object that defines the DataStream program in the main() method */
object AverageSensorReadings {
/** main() defines and executes the DataStream program */
def main(args: Array[String]) {
// set up the streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// use event time for the application
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// configure watermark interval
env.getConfig.setAutoWatermarkInterval(1000L)
// ingest sensor stream
val sensorData: DataStream[SensorReading] = env
// SensorSource generates random temperature readings
.addSource(new SensorSource)
// assign timestamps and watermarks which are required for event time
.assignTimestampsAndWatermarks(new SensorTimeAssigner)
val avgTemp: DataStream[SensorReading] = sensorData
// convert Fahrenheit to Celsius using an inlined map function
.map( r =>
SensorReading(r.id, r.timestamp, (r.temperature - 32) * (5.0 / 9.0)) )
// organize stream by sensorId
.keyBy(_.id)
// group readings in 1 second windows
.timeWindow(Time.seconds(1))
// compute average temperature using a user-defined function
.apply(new TemperatureAverager)
// print result stream to standard out
avgTemp.print()
// execute application
env.execute("Compute average sensor temperature")
}
}
- Transformation
- Stream API programming は複数の変換処理をつなぎ合わせることと同義。またユーザーロジックも User defined function の transformation として扱う
- Basic transformations
- Map, Filter, FlatMap (一つの入力から、0から複数の出力。Map と Filter を組み合わせて汎用化したもの)
- KeyedStream transformations
- KeyedStream は DataStream を特定のキーで論理的にパーティショニングしたしたもの。同じキーのイベントは同じ状態にアクセスできる
- KeyBy
- キーを指定し DataStream から KeyedStream を生成する
- Rolling aggregations
- sum, min, max などを KeyedStream に適用し DataStream を生成する
- Reduce
- Rolling aggregation の汎用版で、Reduce関数を全要素に適用して集約する
- Multistream transformation
- Union, Connect/coMap/coFlatMap (SQL の join に近い), Split and select
- Distribution transformations
- アプリケーションレベルでデータをパーティショニングしたい場合。通常は Flink が自動で割り振るが、skew がある場合などに使う
- random, round-robin (rebalance), rescale (送信先のサブセットに対してのラウンドロビン), broadcast, global, custom
- Parallelism の設定
- 環境ごととオペレーターごとの設定値がある
- 環境ごとのものは、例えばローカル起動だと CPU のコア数がデフォルト
- オペレーターごとに上書きできる。その際に環境の値を取得してそこからの相対値の指定も可能
- Types
- Flink は型情報をもとにデータを伝搬している。特に型に応じて独自のシリアライズを行い効率化している部分もある
- fallback として汎用型として扱われ Kyro を使ってシリアライズされるケースもあるが、パフォーマンスは劣る
- 対応している型
- Primitive (Java, Scala のプリミティブ型)
- Tuples
- Scala case classes
- POJOs (Apache Avro で生成されたクラスも含む)
- Special types
- 型情報は TypeInformation クラスで管理されている
- 通常 Flink は適切な型を推論するが、明示的に指定することもできる
- Flink は型情報をもとにデータを伝搬している。特に型に応じて独自のシリアライズを行い効率化している部分もある
- Functions の実装
- Function Classes
- プログラムが submit されると、Java の serialization でシリアライズされ各ワーカーに配られる
- そのタイミング以降は変更はできない。イベントに応じた初期化などはできない
- Lambda Functions
- Rich Functions
- 初期化とファイナライズを行う
open(),close()がある getRuntimeContext()が提供されており、タスクの parallelism, subtast index, task name, partitioned state などの情報にアクセスできる
- 初期化とファイナライズを行う
- Function Classes
6. Time-Based and Window Operations
- StreamExecutionEnvironment で TimeCharacteristic を設定する
- ProcessingTime, EventTime, IngestionTime (イベントが Flink に到達した時刻を Event time とみなす)
- Timestamp のアサインと Watermark の生成
- millisecond 単位の epoch time を使う
- SourceFunction (後述) または UDF でアサインと生成を行う
- TimestampAssigner インタフェースを実装する
- できるだけ Source の近くで実行することが推奨されるが、タスクのリディストリビューションに影響しなければ任意の箇所でもよい
- event time 依存の transformation を行う前にアサインする必要がある
- 繰り返しになるが Watermarks は正確性とレイテンシのバランスを取る必要がある。バッチ処理構成ではなかった、区切りのないイベントを扱うストリーム処理の本質的な特徴である
- Process functions
- これまで見てきた DataStream API の関数は timestamp へのアクセスが制限されていたが、これらは Process Function という低レベルの API の上に実装されている
- ProcessFunction は RichFunction を実装している、つまり
open(),close(),getRuntimeContext()を提供している - 加えて、
KeyedProcessFunction[KEY, IN, OUT]を例にとると、以下の 2 つのメソッドを提供しているprocessElement(v: IN, ctx: Context, out: Collector[OUT])- Context が通常の関数との大きな違いで、timestamp へのアクセスはここから可能になっている
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])- 事前に登録された Timer がトリガーされた際に呼び出されるコールバック
- こちらも timestamp へのアクセスが可能
- TimeService
- 現在時刻の取得、タイマーのセット、タイマーの削除ができる
- 設定したタイマーが発火すると前述の
onTimerが呼び出される
- Side outputs
- 通常は一つの出力を下流に流すだけだが、Process functions はその他に Side outputs という別の出力をすることができる
- CoProcess functions
- 2 つの入力ストリームを受け取り、それぞれのイベントに対して処理を行う。CoFlatMapFunction と同様の機能を持つが、こちらは Context がわたってくるのでタイマーや Side output が可能
- Window operators
- 区切りのないストリームを一定のグループ (Bucket) に区切り、そのグループに対して処理を行う
- Window operator は 2 つの構成要素から成る
- Window assigner: 入力ストリームをどう window にグループ分けするかを定義する。window assigner は WindowStream を生成する
- Window function: WindowStream に適用される処理
- Window は最初の要素がアサインされた際に作成される。Finlk は空の window を評価しない
- Built-in Window Assigners
- Tumbling widows
- 固定の時間間隔のウインドウ。オーバーラップなし
- Sliding windows
- 固定幅でインターバルごとにスライドする
- インターバルがウインドウ幅より小さければオーバーラップするし、大きければ間のイベントは欠損する
- 固定幅でインターバルごとにスライドする
- Session windows
- イベントとイベントの間が一定以上インアクティブな場合に別バケットとする
- Windows への関数の適用
- 関数は2種類に分類できる
- Incremental aggregation function: イベントがウインドウに追加されるたびに計算する。空間効率がよい
- ReduceFunction, AggregateFunction
- Full window functions: ウインドウ内の全イベントをループして計算する。より複雑なロジックを実現できる
- ProcessWindowFunction (Context として Window の開始終了時刻や、グローバル・ウインドウごとの状態へのアクセスが可能。内部的にそのウインドウのイベントが全て List で保持されており、複雑なロジックが実装できる)
- Incremental aggregation function: イベントがウインドウに追加されるたびに計算する。空間効率がよい
- Reduce などの Incremental な関数の第二引数に ProcessWindowFunction を渡すことで、届いたイベントごとに Reduce などを適用した後に ProcessWindowFunction を適用するということもできる
- 関数は2種類に分類できる
- カスタムの Windows 関数の定義も可能
- windows の Lifecycle
- Assigner が最初の要素を追加したときに作られる
- Window ごとに以下の要素を持つ
- Window content: incremental aggregation が適用された後の計算結果
- Window object: window ごとに別のオブジェクト。開始終了時刻などを持つ
- Timers and triggers
- Windows の評価や削除のタイミングでトリガーする
- カスタムの状態
- Window の破棄時に content や object も破棄されるが、カスタムのトリガーや状態は自動では破棄されず、自身でちゃんと掃除しないとリークする
- windows の Lifecycle
- Joining streams on time
- 複数のストリームを結合するために、Interval joinと window join というビルトイン関数が準備されている。またカスタムロジックも実装できる
- interval join
- 指定したインターバルの期間内のイベントでキーが一致したら結合する
- Inner Join のセマンティクスを提供する。つまりマッチするレコードがなければ破棄される
- window join
- assigner が振り分けて同じ window に入ったもの同士で結合する
- Handling late data
- Dropする。最もシンプルでデフォルトの動作
- 別のストリームに Side output で流す。それをどう処理するかは要件による
- 再計算し更新を伝搬する
- 実現には以下の2点がクリアになっていないといけない
- 計算済みのウインドウ、状態をどれだけ保持し続けるか
- Allowed lateness というパラメータで調整する
- Sink 先が後からの更新に対応しているか
- 計算済みのウインドウ、状態をどれだけ保持し続けるか
- 実現には以下の2点がクリアになっていないといけない
7. Stateful Operators and Applications
- Statefulな関数の実装
- KeyedState
- Keyed Steamのみ
- 同じキーを処理する並列タスクがスコープ
- 単体の値やList, Map, ReduceState, AggregateState
- StateDescriptor を登録する
- Operator List State
- オペレーター単位のスコープ
- スナップショットをとる時やリストアする時の処理を実装する必要がある
- スケールイン、アウトに合わせて状態も統合、分割する必要があり、その実装を行う必要がある
- Broadcast State
- 例えば高温検知システムで閾値を動的に変えるような場合に閾値を前オペレータにブロードキャストするというユースケース
- CheckpointedFunction interface
- チェックポイントと状態の整合性を管理するためのインタフェース
- オペレーターの起動時、再起動時に初期化を行う関数と、チェックポイント取得直前に呼び出される状態のスナップショット取得関数を実装する
- 例えば exactly-once を要求する sink への書き込みは、checkpoint が完了した時点のデータを書き込まないと、障害時に再計算されデータが変わる可能性がある。そのような要件のオペレーターのために JobManager から checkpoint の完了通知を受け取るインタフェースもある
- KeyedState
- Checkpoint 作成の有効化
- 明示的に有効化する必要がある
- Checkpoint 取得のインターバルはアプリケーション全体のパフォーマンスと障害復旧時間のトレードオフになる
- インターバル以外にもチューニングポイントがある。保証レベル(exactly-once or at-least-once)、checkpoint 並列数、checkpoint のタイムアウト、backend特有のパラメータなど
- Savepoint 利用時に必須の設定
- オペレーターごとの unique identifier と Keyed State operator の最大並列数の指定がされていないと、Savepoint を適切に利用できない
- 前者がないと状態をどのオペレーターに割り振れば良いか判断できない。後者もデータの分散に影響があるので必須
- Savepoint が利用できないとアプリケーションの改修やデバッグが極めてしづらくなる
- オペレーターごとの unique identifier と Keyed State operator の最大並列数の指定がされていないと、Savepoint を適切に利用できない
- 頑健性とパフォーマンス維持
- どのようなセットアップにするかによって変わる
- State Backend
- Memory
- TaskManager のメモリ上に状態を保存し、JobManager のメモリ上に Checkpoint する
- 高速だが、それぞれの JVM プロセスのメモリサイズまでしか状態を持てず、必然的に GC されやすい。また JobManager の障害からは復旧できない
- 基本的には開発環境用
- Fs
- 状態は引き続きメモリ上に持つが、checkpoint は外部ストレージに保存する
- レイテンシを維持しつつ永続化もできるが、TaskManager のメモリサイズの制約と GC されやすいという制約は残る
- RocksDB
- 大きいサイズの状態が必要な場合の選択肢。テラバイト水準での実績もある
- その分メモリに比べるとレイテンシは劣る
- Memory
- RocksDB のようにデータをシリアライズして格納するバックエンドの場合、その実装方法とどの型を使うかでパフォーマンスが大きく変わる
- 例えば ValueState は全体をシリアライズ、デシリアライズするが、MapState はキーごとにシリアライズされるので、高速になるケースもある
- アプリケーションを長期間稼働させるには状態が肥大化しないことが重要
- 状態はオペレーターの要件と深く関わっているので、Flink が自動で各状態をクリーンアップすることはできず、各オペレーターにその管理の責任がある
- よくあるケースは Keyed State に stale key が残り続けるというもの。expire したものはクリアする
- またビルトイン関数であっても状態のクリーンアップは自前で行う必要がある。例えば KyedStream の aggregation は一定の範囲のキーが何度も登場するストリームを前提としている
- Stateful Application の拡張
- アプリケーションの更新は savepoint 取得、旧アプリケーションの停止、savepoint からの新アプリケーションの起動という手順で行われるので、新旧で savepoint compatible である必要がある
- savepoint の互換性にはオペレーターの識別子と状態名の一致が必要
- 更新は 3 つのケースに分類できる
- 1. 既存の状態は変更せず、ロジックを更新、または新しい状態を追加する
- このパターンでは常に savepoint 互換性は保たれる。新しい状態は空で初期化されるだけ
- 2. 状態を削除する
- デフォルトでは Flink はすべての状態がリストアできなければアプリケーションを起動しない。そのためこの safety check を明示的に一時無効化し新アプリケーションを起動する必要がある
- 3. 状態の型やプリミティブを変更する
- 1.7 時点では、一部の型変更は可能だが、プリミティブの変更はサポートされていない
- 前者は Apache Avro の schema evolution rules の範囲内で可能
- コミュニティから要望の多い機能だがまだ実現されていない
- 1.7 時点では、一部の型変更は可能だが、プリミティブの変更はサポートされていない
- Queryable State
- ストリーミングアプリケーションの処理結果は sink のデータストアに書き込まれ別のアプリケーションから参照されるのが通常の構成
- Flink は Queryable State という機能を提供しており、アプリケーション稼働中の各状態を外部から read-only で参照できる
- この機能によりリアルタイムダッシュボードなど一部のユースケースの実装が容易になる
- TaskManager ごとに Proxy プロセスが動作し、クライアントからのリクエストに応じて JobManager にその状態を管理する TaskManager やキャッシュの有無を問い合わせる
- Query 可能な状態はストリーミング処理のコード上で指定する
8. Reading from and Writing to External Systems
- Application consistency guarantee
- エンドツーエンドの一貫性の保証には source と sink 側の対応も必要になる
- source はチェックポイントからのリプレイに対応していないと、At-most-once 保証相当になる
- sink は冪等性を持つか、transactionalな書き込みに対応していないと At-least-once 相当になる
- 冪等に処理を行える sink の場合、最終結果は exactly-once 相当になる
- ただしリカバリ中に過去のデータが見えてしまうという一貫性の崩れが起こり得る
- transaction の実現には WAL と 2PC のアプローチがある
- 前者はチェックポイントが確定した WAL のみ sink に送る。一度に sink に書き込まれる量がスパイキーになるリスクがある
- 後者はストリーミングアプリケーションと sink 側で 2PC を実現する
- 冪等に処理を行える sink の場合、最終結果は exactly-once 相当になる
- Provided connectors
- Apache Kafka
- Source
- Kafka の各パーティションのオフセットをリーダーが checkpoint として保持している
- Kafka 0.10.0 以降は message timestamp に対応しており、Flink はこれを event timeとして使う
- sink
- at-least-once 保証の場合、書き込みに失敗した際には指定した回数のリトライを行う
- exactly-once の場合はトランザクション機能が使われる
- ログを uncommitted 状態で記録し、確定後に committed ラベルを付ける。consumerは分離レベルに応じて uncommitted なレコードを読み取るかを決める
- 長時間 open なトランザクションは timeout 設定に応じて自動でクローズされる
- そのため、Flink 側でリカバリに時間がかかりすぎた場合などに、この Kafka 側のタイムアウトを超えないよう注意する
- Source
- Filesystem
- source
- 与えられたパスのファイルをスキャンし、ファイル名とその中のレンジに分割し、複数のタスクにそれを渡して並列読み込みをする
- ワンショットの読み取りが、mtime ペースの継続読み取りが可能
- 後者の典型的な実装パターンは、ファイルを書き込み、完了後にそれを Flink がモニターしているディレクトリに mv するというもの
- filesystem を source とする場合、watermark の生成は単純ではない。複数に分割され複数のリーダーで読み取りをしているものの中から、最小の timestamp を特定する必要がある
- sink
- ローテーションの設定や encoding の設定 (行ごと、全体をバルクで) などの設定もできる
- in-progress/pending/complete 各状態でファイルを管理し、checkpoint がとられたものが complete としてコミットされる。この機構で exactly-once が実現される
- source
- Apache Cassandra
- sink connector を提供
- デフォルトでは casandra の upsert semantics を利用した、eventual excatly-once 保障が提供される
- 一時的な inconsistency も許容できない場合は WAL モードを使うとよい
- Apache Kafka
- Custom Source Function
- Source|RichFunction (1並列用) と (Rich)ParalllelSourcFunction (複数並列用) というインタフェースが提供されている
- それぞれ run() と cancel() を実装する
- これまでに述べたように、Flink の checkpointing 機構と連携した読み取り位置 (やファイルパス、パーティション ID などのメタデータ) を保持し checkpoint として永続化すること、savepoint からの起動ではその情報を復元すること、savepoint なしではデフォルト値から開始することが、一貫性の保障のためには求められる
- また run() メソッドは別スレッドで動作するので、checkpoint 取得中は読み取り位置を前に進めないよう、ロックなどで保護する必要がある
- Source function で timestamp と watermark を生成するのがベター
- 複数並列で読み取る場合は、それぞれの source ごとに watermark を生成する必要がある
- source が stale した際に、source function はそれを検知して idle 状態に遷移する必要がある。前述したようにそうしないと watermark が進まず、アプリケーション全体が滞留してしまう
- Source|RichFunction (1並列用) と (Rich)ParalllelSourcFunction (複数並列用) というインタフェースが提供されている
- Custom Sink Function
- 冪等性を持つ sink との連携の場合、レコードを特定できる識別子があること、sink 先がそのキーでの upsert に対応していることが必要とされる
- transactional なアプローチの場合、WAL 方式か 2PC 方式かが必要になる。それぞれのテンプレートがありそれを実装する
- WAL
- GenericWriteAheadSink の sendValues() を実装する
- WAL 方式は次のケースで厳密な exactly-once にはならない
- sendValues() の途中で失敗した場合。特に sink バルクインサートに対応していない場合、途中までのレコードが書き込まれていて、その後もう一度おなじ書き込みが走ることになる
- sendValue() は成功したが、その後 CheckpointCommitter の呼び出し前や呼び出し中に失敗した場合。やはり全レコードが再度書き込まれる
- 2PC
- 基本的に重いプロトコルなので、本当に必要かは吟味したほうがよい
- 2PC を採用するには sink は以下を満たす必要がある
- transaction サポート (または sink function によるエミュレーション)
- transaction を open し checkpoint interval の間に追加の write を受け付けられること
- checkpoint completion notification を受け取るまでコミットを待てること
- もし sink が timeout でトランザクションをクローズした場合、その間のデータはロストする
- Cassandra sink はこのケースではデータをロストするので、条件付きの exactly-once 保証になる
- 問題発生時にはトランザクションを復旧できること
- transaction id を発行し、それに対してコミットかロールバックを発行できる sink もある
- transaction のコミットは冪等であること。同じ transaction id への複数回のコミットがありえる
- WAL
- オペレータ内で POST API を呼び出すなど、ストリームアプリケーションに sink は必須のものではない。ただ exactly-once の保障などが必要な場合は sink の機構を利用したほうがよい
- 外部システムへの非同期アクセス
- source と sink 以外に、ストリームの途中で外部システムに問い合わせ、入力値の情報を補完するというユースケースがある
- 例えば https://github.com/yahoo/streaming-benchmarks にはクリックデータにキャンペーン情報を補完するというパターンがある
- 単純にオペレータ内で同期的にに外部へクエリし結果を待っていると、全体のレイテンシが悪化する
- 非同期なアクセス手法が提供されており、この問題を緩和できる
- event-time, watermark や savepoint の考慮もされている
- source と sink 以外に、ストリームの途中で外部システムに問い合わせ、入力値の情報を補完するというユースケースがある
9. Setting Up Flink for Streaming Applications
- セットアップに関しては、概要は以前の章でカバーされており、詳細は実際に必要な部分をその時参照した方が良いので、メモは割愛
- パラメータチューニング
- cpu
- 明示的なパラメータはない
- TaskManager ごとに最大何スロット起動できるかの設定はある
- 主にスタンドアローンクラスタ向けのもので、k8s 上などに展開するクラスタの場合 pod ごとに 1 slot とし pod 数自体を伸縮させた方がわかりやすい
- 後述のメモリ管理的にも、例えば jvm のヒープサイズはその上で動く slot 全体で共有になるので、1 slot ごとの方がやはり管理しやすい
- memory
- まずは jvm のヒープサイズ
- master プロセスは中程度のスペックで良いが、TaskManager はそれよりも豊富な方が良い
- ネットワークバッファのメモリ使用量も多くなる傾向がある
- Netty library が使われており、接続先ごとにネットワークバッファを持っている
- タスクの並列度や組み合わせによって、接続数は大きく増えることがある
- ネットワークバッファは native (off-heap) memory に確保される
- RocksDB のメモリ使用量も増加することが多い
- どの程度になるかはワークロードによる
- まずは jvm のヒープサイズ
- Disk storage
- JAR ファイル、ログ、RocksDB バックエンドの場合の状態保持などで、 disk storage を利用している
- Checkpoint and state backend
- コードレベル、アプリケーションレベルでの指定が主だが、クラスタレベルでのデフォルト値も指定できる
- バックエンドによりサポート状況は異なるが、async checkpointing や incremental checkpointing はパフォーマンスに影響する
- Security
- Kerberos 認証や内部、外部通信の SSL 化に対応している
- cpu
10. Operating Flink and Streaming Applications
- Streaming application の運用
- Savepoint は checkpoint とは異なり、手動でトリガーする必要があり、また自動では削除されない
flinkcli tool- job id: アプリケーションの識別子
flink savepoint <jobId> [savepointPath]で savepoint を取得flink savepoint -d savepointPathで savepoint を削除- savepoint の取得が完了するまでは削除してはいけいない。checkpoint と同じように完了 notification に依存する処理がありうるので
flink cancel <jobId>でアプリケーションをキャンセルcancel -s <savepointPath>で savepoint を取得してからキャンセル
flink run -s <savepointPath> [options] <jobJar> [arguments]で savepoint からアプリケーションを起動
- scale-in/out は savepoint からの起動時に設定を変更するだけで良い
- アプリケーション全体の並列数設定ではなく、コード中で指定している場合はリコンパイルが必要になる
- exactly-once を保障している場合は
cancel -sで savepoint を取得してからキャンセルすること - アプリケーション全体の並列していだけで構成されている場合は
flink modify <jobId> -p <newParallelism>というコマンドだけで変更が可能
- cli tool の内部では REST API を利用している。直接 REST API を利用することも可能
- ここまでは fremework style depolyment の話だったが、前述のように library style もある
./flink-container/docker/build.shでイメージを作成し、./flinc-container/kubernetes配下の yaml テンプレートを参考に構築できる
- Controlling task scheduling
- Task chaning の制御
- 複数の処理を 1 スレッドにまとめ、データ転送のオーバーヘッドをなくす task chaning はデフォルトで有効になっている
- ただし自動判定で結合・分断されたものが最適で無い場合、無効化することもできる
- 特定のオペレータに対して明示的に chain させる、させない指定もできる
- Slot-sharing group
- オペレーターをどのスロットグループに所属させるかを明示できる
- 同じグループのオペレーターはそのグループのスロットで実行される
- 各グループに何スロット割り当てられるかは parallelism 設定により割り出される
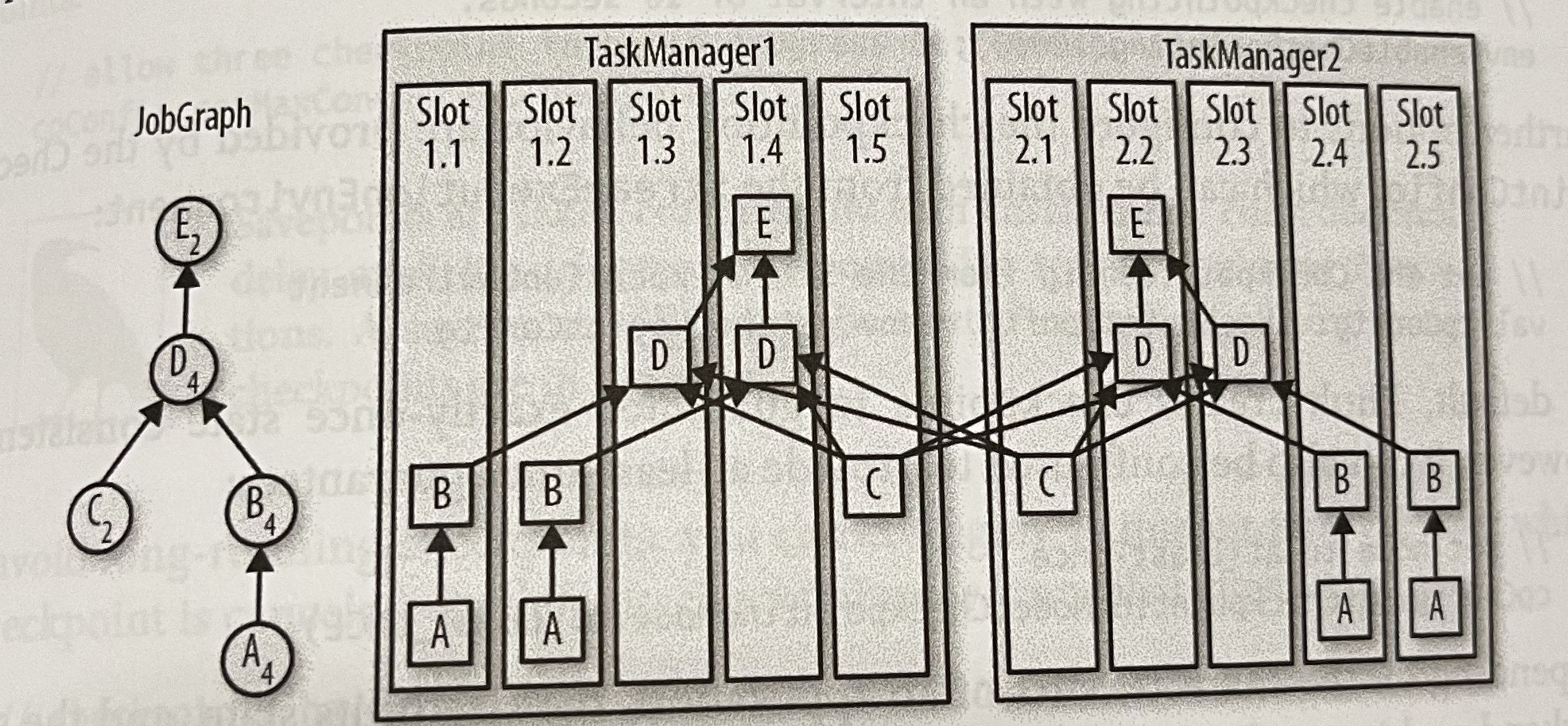
Figure 10-1. Controlling task scheduling with slot-sharing groups より引用
- Task chaning の制御
- Checkpointing のチューニング
- 取得するインターバル
- 保証レベル (at-least-once or exactly-once)
- 前回の取得からの最少インターバル
- チェックポイントの取得完了までに時間がかかるケースのため
- 並列数
- タイムアウト
- エラー時の挙動(例外を出して再起動するか否か)
- 圧縮の有無(バックエンドのサポート状況にもよる)
- アプリケーションエラー時にチェックポイントを保持するかどうか
- State backend のチューニング
- メモリ: 非同期のオンオフ、最大サイズ
- FileSystem: パス、非同期のオンオフ
- RocksDB: パス、インクリメンタルバックアップのオンオフ
- Recovery のチューニング
- リカバリ時には入力が溜まっている。最新にキャッチアップするよう十分なリソースが必要
- 時には何度再起動しても失敗し続けるケースもある。そのため再起動には3つのモードがある
- 固定のインターバル後に再起動
- ある期間にある回数だけ失敗できるという割合を指定し、その範囲内で再起動
- 再起動しない
- 同じマシンでの再起動など、チェックポイントが外部ストレージだけでなく内部にも残っていることがある。local recovery を有効化するとそのようなケースでの復旧が速くなる
- あくまで source of truth は外部ストレージ
- 監視
- 出発点としてはバンドルされている Web UI がある
- Prometheus など各種監視バックエンドへのメトリクスの連携も可能
- 独自のメトリクス定義も可能
- レイテンシの計測
- 各イベントの厳密なレイテンシを計測するのは分散システムでは非常に難しい
- そこで flink ではレイテンシ計測用の特殊なイベントを source から流し、sink に到達するまでの時間を計測することでレイテンシを概算している
- この専用イベントは latency marker と呼ばれる。利用時にはインターバルを指定する
- ロギング
- デフォルトは log4j で logback にも対応している
11. Where to Go from Here
- 本書では紹介していないハイレベル API
- DataSet API
- バッチ処理が可能になる
- Table API
- SQL を解釈しジョブグラフに落とし込んでくれる
- FlinkCEP
- 複雑なパターンマッチ。金融、不正検知、異常の監視などがユースケース
- Gelly
- グラフの作成
- DataSet API
- コミュニティ
- Mailing list
user@flink.apache.orgdev@flink.apache.orgcommunity@flink.apache.org
- Blogs
- Meetups, conferences
- Mailing list